第十三章 声源分离技术
在远场语音识别场景,会遇到同时有多个人说话的场景(鸡尾酒效应),也可能会遇到周围有噪声源的情景(电器,风扇等),前面章节的方法基于单个麦克风并不能获得很好的性能,基于多通道的声源分离可以获得更好的效果。 和基于单麦克的语音增强技术相比,多通道语音增强技术利用阵列带来的空间信息使得在降噪性能提升的同时语音失真度更小。基于DD的方法相较ML在估计语音存在概率SPP具有更大的优势。
声源分离技术主要分为三类:
1.波束形成技术(BF, beamforming) 2.盲源分离技术(BSS, blind source seperation) 3.时频掩码技术(T-F masking, time-frequency masking)
以上单个方法是可以实现声源分离增强信噪比(SNR)的,但是也有将上述类别融合的方法。本偏文章主要是阐述各个方法的基本思想和基本原理,了解了这些后,可以看第十一章,将BF和T-F技术集合在一起的一个声源分离的c代码实例。
声场
对于中高音,声音在室内以反射和散射为主,这一过程不断重复和往复直到能量变成零(吸收和传输损耗),这一过程约有16次之多。对于低音室内更像一个谐振腔,波长满足谐振条件的声波将会被放大,随着说话位置的位置变化,增强和对消的低音频率也会变化。
Schroeder frequency: 室内声音的谐振腔频率和反射/散射频率的分界点。对于居家室内场景该频率一般在100Hz~200Hz之间,在室内播放一个谐振频率的声波,人在室内不同的位置听到的音量差异是比较明显的,而对于中高音差别并不明显。
- 散射噪声场
散射噪声场中,噪声能量向各个方向传播的概率是相等的。 包含若干个来自方向上均匀分布的相位随机的平面波,
假设空间中任意一点的声波压强表达式如下:
位置向量,参考点可以任意选取,则另外一点的声压表达时如下:
其中是平面波的波数向量。
相干和非相干噪声
- 波数(k)
沿着波的传播方向单位长度内波的全周期数。,也可定义成,这样可以理解成相位随距离的变化率。
远场和近场
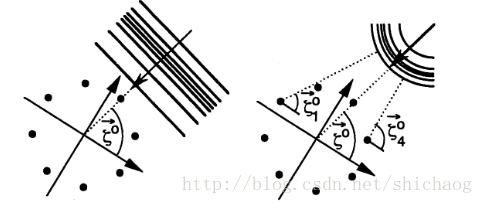
远场模型可以看成是平面波(左),传播方向是,远场要看成是球面波(右),传播方向
远场和近场的临界值是(d为两个阵元之间的距离, 是声波波长最小值),当声源距离大于临界值时,使用远场模型,反之使用近场模型。
波束形成技术
利用空域滤波的方法,处理噪声,干扰和混响,提升语音信号质量。声音的分离和降噪,也可以用在其声源定位和跟踪。
波束形成的时频域解释
信号到达的时间差,产生了时延差,对应到频域里,是频域相位变换。在波束形成上,主要分为时域方法和频域方法两大类;时域里的方法,主要是将信号延迟差调成零再相加,在频域里主要是进行相位变换再相加。信号最初是通过ADC从模拟转换成数字,这一转换过程是时域的方法,在频域里还要做傅里叶变换,这一变换过程常采取信号分段再做FFT变换,为了减小信号分段带来的边缘效应,FFT时重叠的长度应当是分段的长度的50%。
它们的核心解释是将据进行相移和幅度移动进行相加处理。超指向波束形成是相对于delay-sum波束形成而言的,在阵元间距是波长的一半时, N个阵元获得的最大增益是10logN,当波束最大增益超过该值时,成为超指向方法。
宽带信号波束形成
宽带语音信号处理使用相对波长较小时,可用超指向(super directive)方法获得固定主瓣宽度,超指向波束形成技术对空域白噪声和阵列特性误差敏感,对于利用散射噪声场先验假设的一些波束方法,如MVDR波束形成方法,通常会在权重中加入单位阵然后再求方向向量以增加波束的鲁棒性。对于依赖数据的一些超指向波束形成方法会使用对角加载的方法来增强波束的鲁棒性。
阵列类型
差分麦克风阵列阵元讨论: 线阵,均匀和非均匀,面阵列,圆阵列 对于不同的外界环境几何尺寸以及声源特性,存在最优阵列排布。
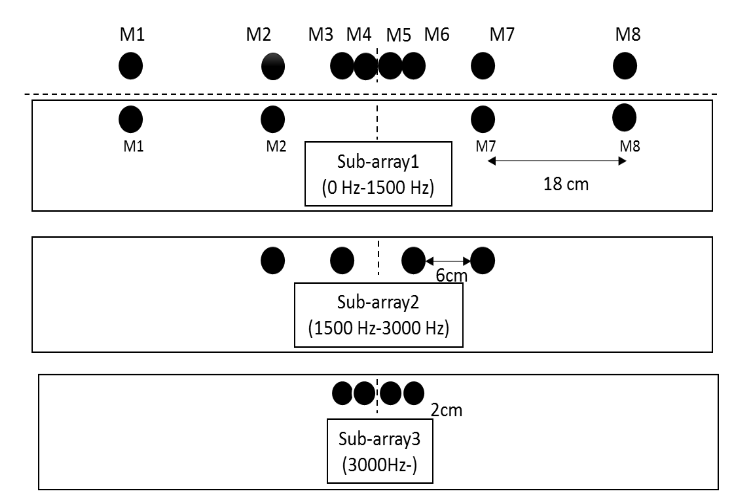
由于语音是宽带信号,其频率从20Hz~20kHz范围,不同的频率群延迟不一样,这里就采用了不同的频范围的语音信号使用不同子阵作为其波束输出,以获得较为一致的主瓣宽度。
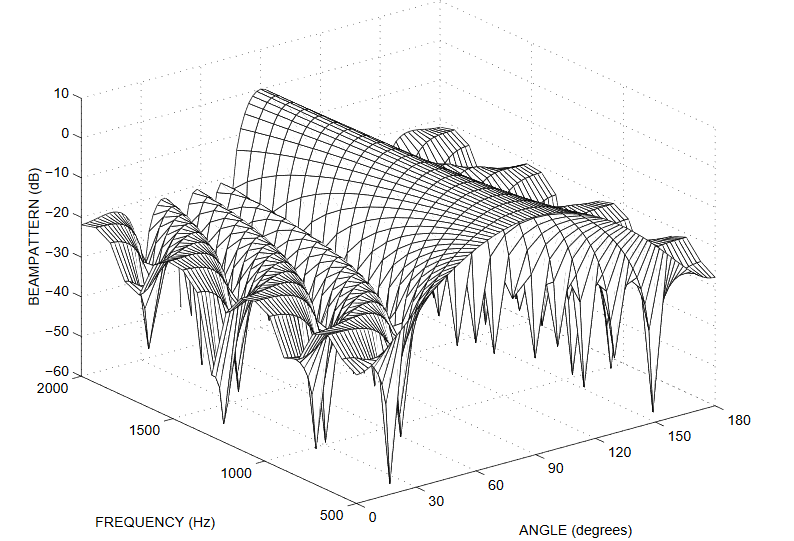
这是均匀阵列的天线方关系图,可以看到主瓣宽度随着频率降低而变宽。
在阅读波束形成方法时,一些频域处理基本知识可以参考下:
3.如果要回顾FFT
3.子带技术
阵元的空间分布以及波束形成的算法对最终的结果都会有影响。
传统(又称经典)的波束形成方法
delay-sum和FIR形式的波束形成,delay-sum可以看成是FIR形式的特例。 这类波束形成的主要出发思想是对某个方向,某些频带进行能量增强(落在主瓣),其它方向(落在旁瓣)和频带减弱,这类波束形成方法主瓣宽度和旁瓣幅度是比较重要的指标,

*表示复共轭,适应于窄带信号。
根据式3,设,当,即相邻点的延迟差为,那么式3可以重写为:

其中是每个通道延迟的阶数,在一些文献中,习惯使用向量来表示上述两个式子:
delay-sum线阵
对于远场阵列模型,任何一个方向传播而来的信号到达不同麦克风的延迟是和麦克风间距,信号传播速度以及入射角相关的值,
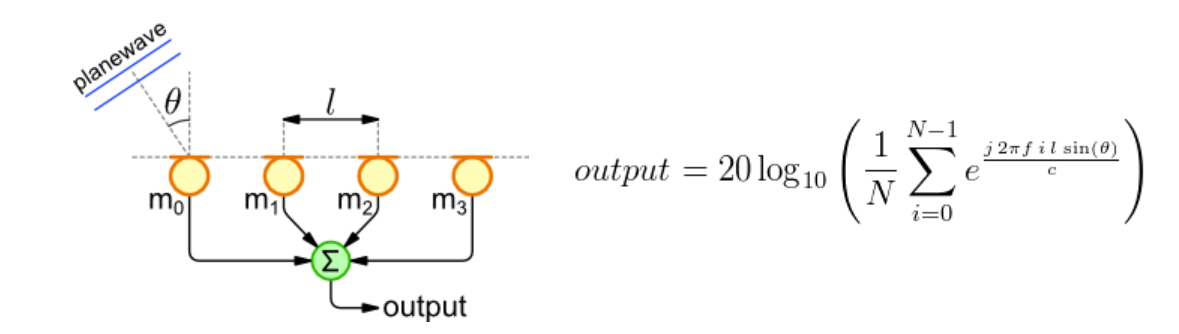
如上图,阵元所在的坐标轴为x轴,与之垂直的是y轴,则相邻两个麦克间的延迟值为:
根据3,7以及8可以得到delay-sum的相应的表现形式和FIR一样,其频率相应可以写为:
向量表示形式是:。其中:
是对复频率的相应,称为方向向量,表示的是对不同的阵元的的相位延迟关系。 在将时域信号变换到频域时,采用ADC模拟器进行等间隔采样,在阵列的时候,空间分布阵元等间距采样(或者非等间距采样),对于线阵FIR滤波和delay-sum的表现形式一致的原因是,它们都是对信号采用了某种类型的延迟再权重相乘。 设式子10.8的表达频域表示为:
波束的方向图定义为。
线阵方向图
线阵模型就是麦克风在同一条直线上。下面绘制的是8麦克,间距1cm时的直角坐标和极坐标图,在直角坐标系中,横坐标是-90度到90度,纵坐标是阵列增益方向图,最高点在横坐标是0度位置,相比第二个峰值约大13dB左右。由极坐标同样可以看出,一圈是360度,从内到外同心圆是增益等高线。从图中依然可以看到增益,另外还有一个指标也可以在这两张图体现出来,即空间分辨率。从直角坐标可以看出约-8~+8度,从这个角度进来的信号相对于其它角度进来的信号会全部被放大约10dB,如果这个角度有多个人声或者离人很近的地方有噪声,则会降低SNR。解决方法是根据使用场景设计合适的空间角分辨率。
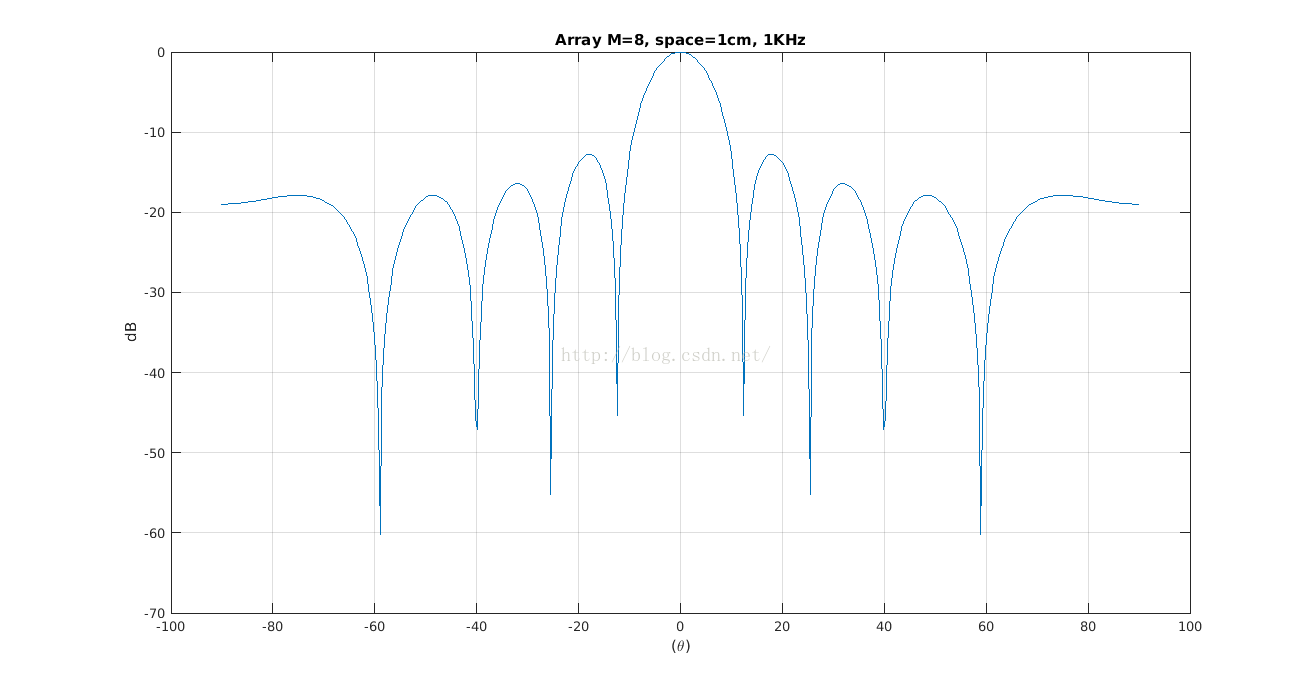
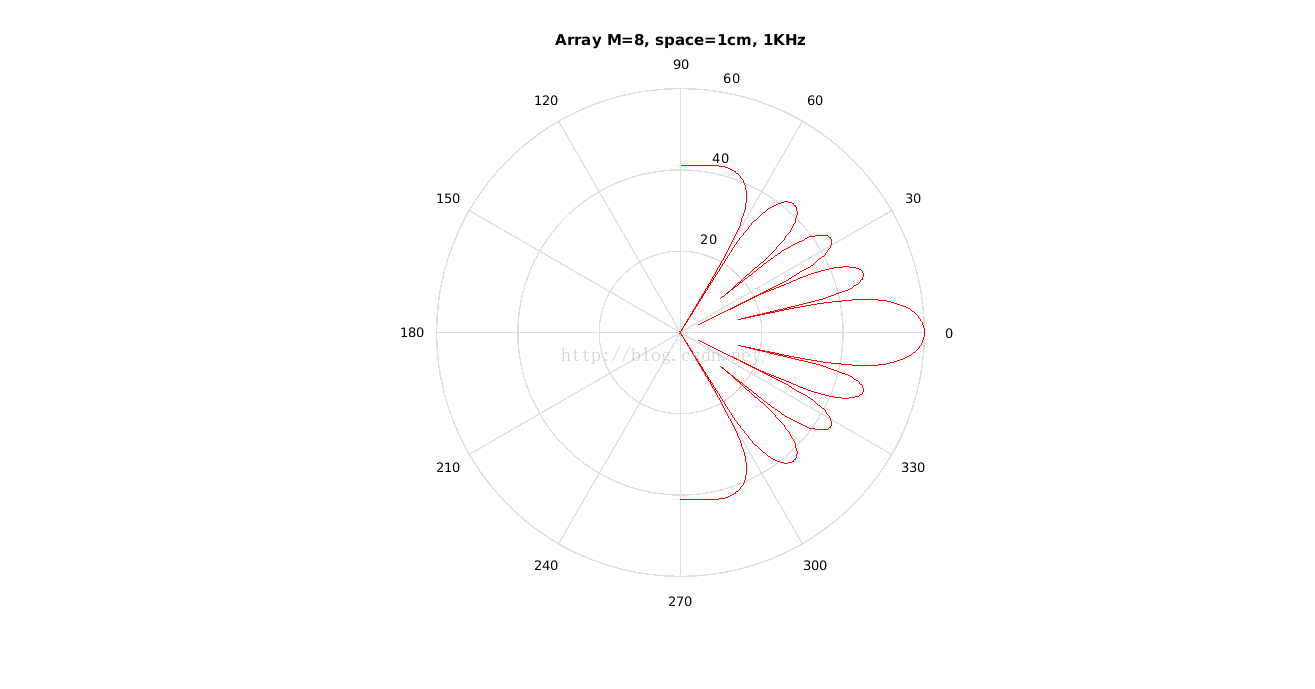
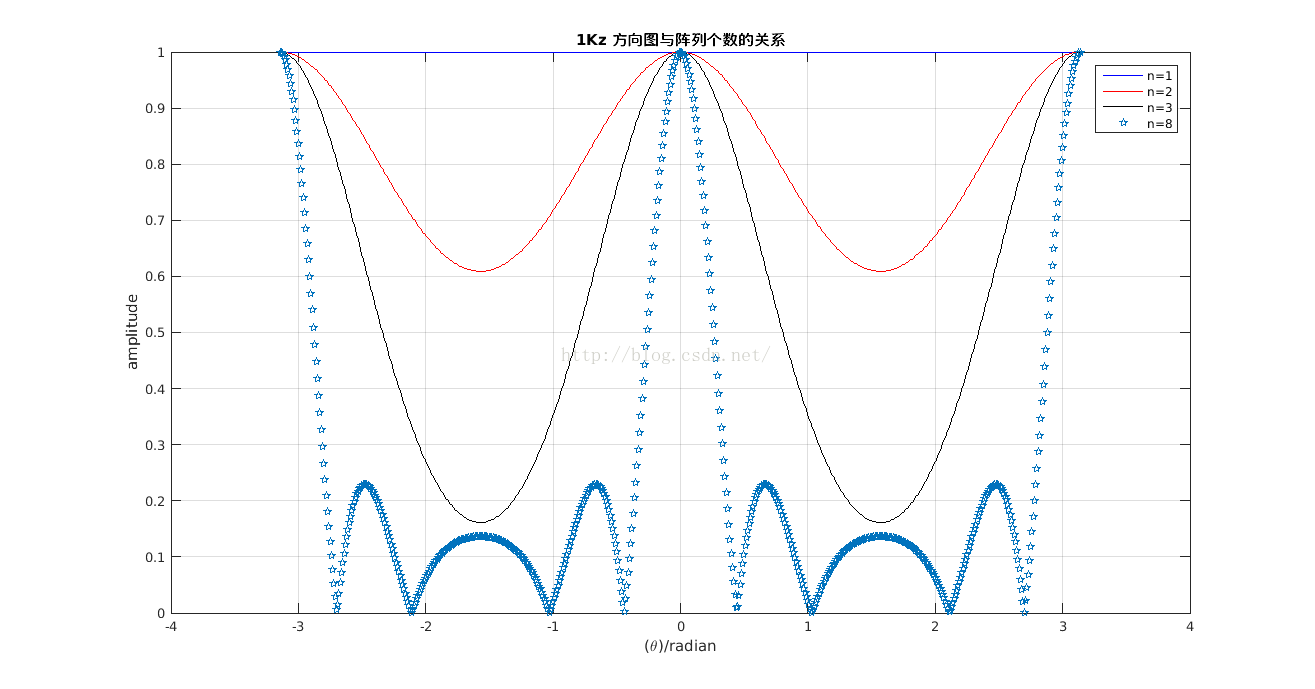
3个麦克可达到的SNR在6dB左右,空间分辨率(3dB带宽)比8麦克大。此处8麦克空域混叠,导致增益下降。
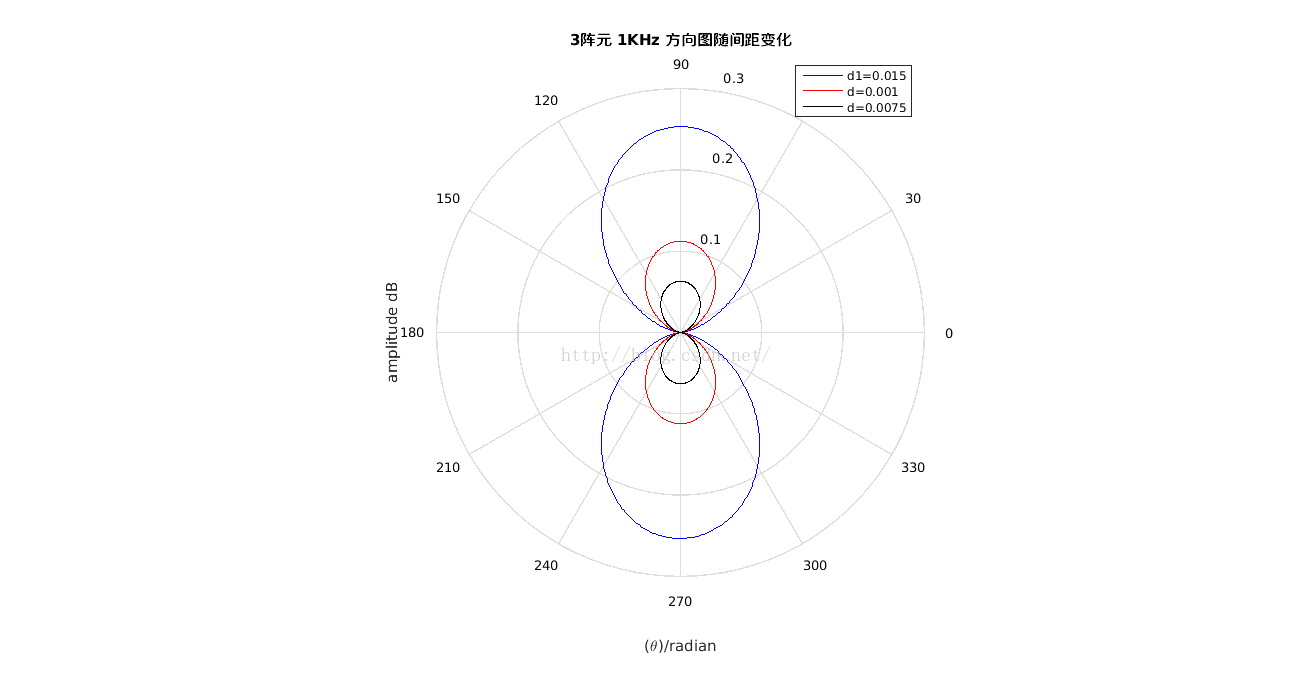
可以看到,图中d的单位是米,即3阵元间距在0.75cm,1cm,以及1.5cm时增益图。即间距越大,可达到的增益越大,但其空间分辨率变低。增益差值超过一倍。
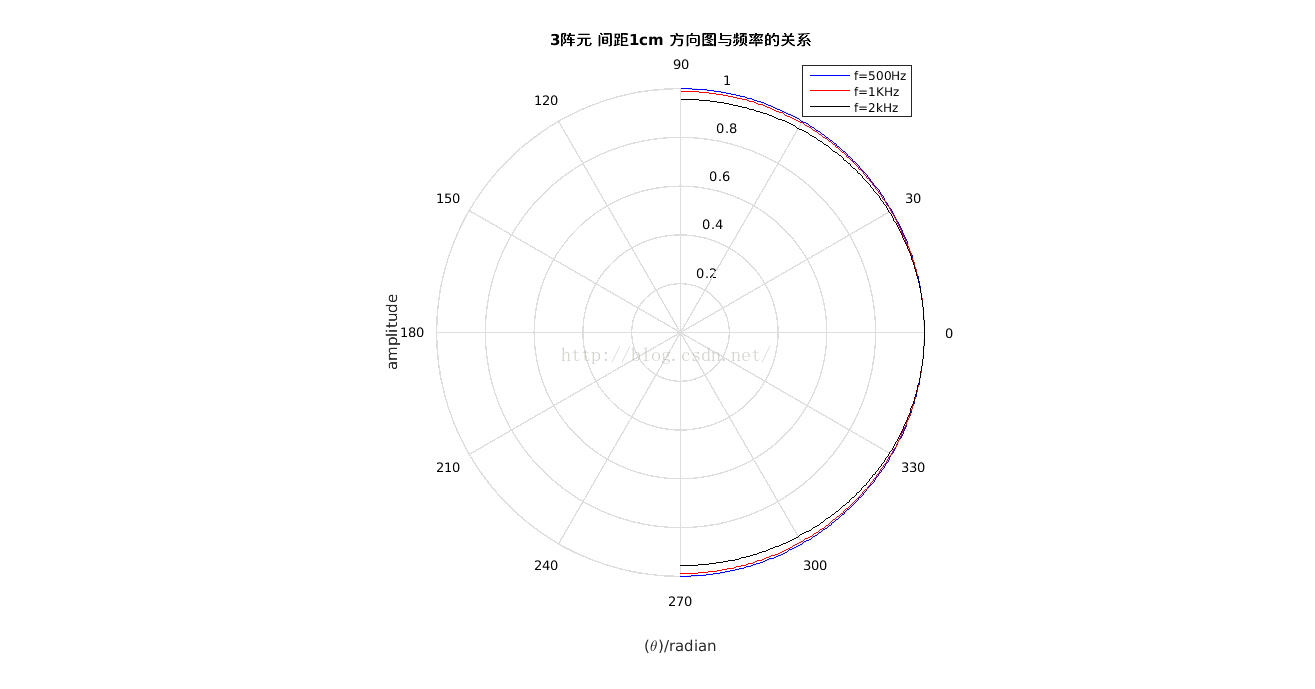
综合来说,3麦克需要考虑麦克风之间间距,输入信号空间分辨率,以及使用场景。间距越大其指向的方向信号增益会越大,但空间分辨率随之降低,线阵模型可得到增益约6dB左右,圆阵增益也可达到这个指标.
filter-sum
利用FIR滤波器实现线性相位变换,以减少对后续依赖相位信息的算法的影响。
对于N抽头的FIR滤波器,其公式表示如下:
其频域和z域表示如下:
可以实现线性相位变换,线性相位是指相频相应是一次函数关系(直线),这就让所有频率的延迟是一样的,因此,这一过程不会引起相位失真或者说延迟失真。对于零频,其延迟为0,幅度是滤波器系数之和(频率为0,带入公式10.14可得)。 线性相位需要滤波器系数是对称的。对于N抽头的FIR滤波器的延迟是。
和delay-sum相比其使用了幅度和相位不一致的权重。

线性相位需要滤波器系数是对称的。对于N抽头的FIR滤波器的延迟是 。
基于统计最优
波束输出能量,如果信号可以看成是平稳过程,则有。

对于LCMV,当delay-sum对所有频满足复常量约束时,有。则LCMV准则可以写成:
采用拉格朗日乘子法求解得到:
如果,则权重系数为MVDR形式的波束形成权重。
自适应波束形成
典型的bf有,Frost beamformer, GSC beamformer, LCMV beamformer, MVDR beamformer。Frost/mvdr等, 基于统计的波束方法,需要信号和噪声的二阶统计量,这些二阶统计量通常是未知的,从观测的数据中近似得到,基于统计量的方法前提条件是信号是平稳过程,语音信号是短时(10ms~30ms)平稳过程,这就需要前面二阶统计量随着时间改变权重,这一改变权重的过程常采用自适应算法实现。 基于目标和干扰声源的统计特性,根据一些准则,如最大信噪比准则(MSNR,maximum signal-to-noise ratio), 最小均方误差(MMSE, minimum mean-squared error),最小方差无失真响应(MVDR, minimum variance distortionless reponse), 以及线性约束最小方差(LCMV, linear constriant minimum variance),其在增强目标信号的同时,抑制干扰信号。

输入数据向量是,其和权重向量的乘积用来估计目标信号值,根据最小均方误差准则,权重的代价函数是:
其中, 以及,对代价函数求导,令其等于零得:
最优权重是:
基于块自适应算法对和的估计基于K个输入信号和。输入信号的自相关矩阵是:
协方差矩阵是:
用于估计自适应权重跟新的速率要大于等于外界噪声(二阶统计量)变化的速率,对于语音信号通常10ms~30ms之间的算是稳态信号。 对于LMS准则,
步长因子决定了权重的收敛特性。
在相干噪声场,可以得到较高的信噪比改善,但是在弱相干噪声场和在散射噪声场中,性能不如固定波束形成。其一种结构可以如下:
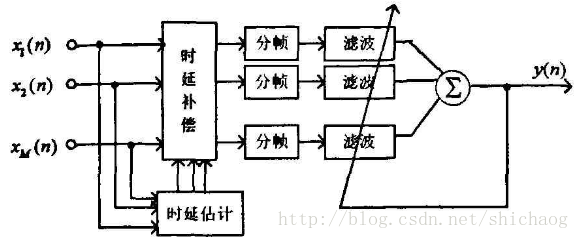
- 后置滤波作用 可以用来去除非相干噪声,但是在相干噪声情况下性能退化,甚至不可用。zelinski后置滤波器的结构体如下:
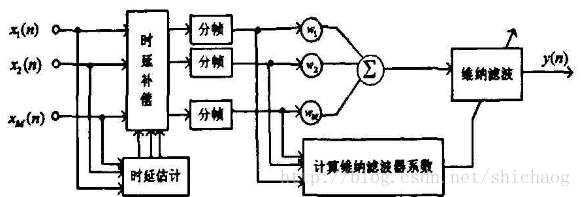
apab(adaptive post-filter for an arbitrary beamformer) 后置滤波器:

通常将自适应滤波器和后置滤波器结合起来以抑制相干和非相干噪声。

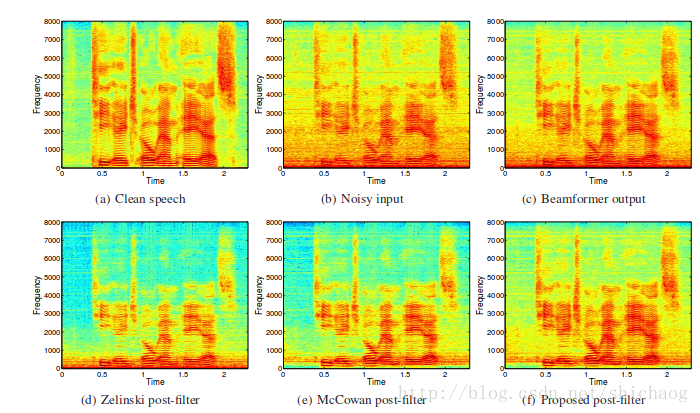
一张频谱图,可以反映它们之间的对比关系:
盲源分离问题
盲源分离技术仅根据观察到的每一路混叠信号估计原始多路信号,独立成分分析(independent component analysis)卷积混合情况的盲源分离技术。第一部分麦克风数量大于声源数量的ICA的方法,第二部分是麦克风数量小于声源数量的时频分集方法,第三部分是基于最大后验概率的单麦克盲源分离技术。 盲源分离解决的问题:
- 线性模型,又称瞬时模型
- 卷积模型,语音更符合这个模型
盲源分离存在两种不确定性:分离后信号的排列顺序和复振幅(幅值和相位)。当源信号之间相互独立时,如果对源信号矢量进行变换,当且仅当变换后的信号之间保持相互独立,该变换矩阵可以分解为一个满秩对角阵和一个转置矩阵的乘积,仅改变源信号的幅度和排列顺序,并没有改变信号波形。
独立分量分析证明了只要通过适当的线性变换,使得变换后的各个信号之间相互独立就可以实现源信号的盲分离,即将盲源分离问题,转换为对独立分量分析的求解问题。可以使用的判决准则:
>1.自然梯度 2.随机梯度 - 信息论法: 1.基于互信息法:对比函数是一个用来衡量变换后各个信号之间相互独立程度的实值标量函数,当且仅当各个输出信号之间相互独立时,对比函数取得最大值或最小值。 2.基于信源的非高斯性测度(仅指峭度) 3.近似负嫡准则,成为FastICA。计算简单,收敛速度快,不需要任何步长参数,且迭代稳定,占用内存少。还可以通过非线性函数的适当选取来找到最优解。
PCA主成份分析。高斯噪声分离。 ICA,非高斯噪声分离,(前提假设线性,静态混合)
- 研究集中于以下几点: 1.欠定问题,源数目多于传感器(麦克风) 2.单通道问题,只有一个传感器,分离出多个源 3.多维BSS, 4.非线性BSS, 5.盲解卷积(声源场景) 6.全局收敛算法 7.非平稳环境下的BSS
- 信号预处理,分离前 1.中心化,即去均值。 2.白化,
| 项目 | 波束形成算法 | 基于ICA的盲源分离算 |
|---|---|---|
| 优势 | 已经商用 | 能够动态跟踪声源 |
| 劣势 | 动态跟踪声源性能差 | 分离矩阵计算量较大;硬件和麦克风成本较高 |
ICA方法
语音信号的卷积盲分离:
- 基于块扩展的自然梯度法
- 空时扩展的FastICA方法
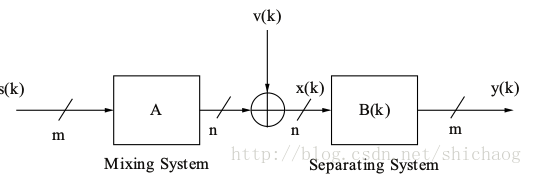
瞬时混合模型BSS分离
是位置语音源数量,观察到$n$个输出。
是矩阵线性时不变系统的系数,是加性噪声。瞬时混合盲源分离技术就是要找到一个$m*n$的解混合矩阵$B$。
然而室内语音由于反射和混响,其要使用卷积混合模型进行分离。
卷积混合分离模型
这里忽略了噪声,其响应的矩阵表示是: 这里要求输入信号之间是统计独立的,短时平稳的。
使用空域独立特性的时域卷积盲分离
使用信源统计独立性进行BSS的方法可以分为两类:
- 基于密度匹配法
- 基于对比函数法
密度匹配法使用自然梯度
对于瞬时混合,仍然可以从ICA的信息最大化的推导出密度匹配法。在线性混合条件下,上面两个准则认为联合概率密度函数如下: 将观察到的信号根据系统解混合矩阵$B$线性变换得到的输出向量$y(k)=B(k)X(k)$,密度匹配BSS方法是使输出向量的概率密度函数匹配模型的概率密度函数$\widehat{p}_y(y)$. 和$\widehat{p}_y(y)$的差异可以使用相对熵(KL散度)来度量: 式中. 此外还有对比函数法等方法频域卷积BSS
对中等程度的混响就需要较长的多通道FIR滤波,这可以放到频域来做,因为时域卷积对应频域相乘。从时域变换到频域可以通过滑窗DFT或者通过短时傅里叶变换(STFT)。窗长内的信号要是准静态的,将T时间内的采样点写成矩阵$X(k)$: 其DFT如下: 做FFT通常会进行加窗处理。观测信号和源信息源的关系如下: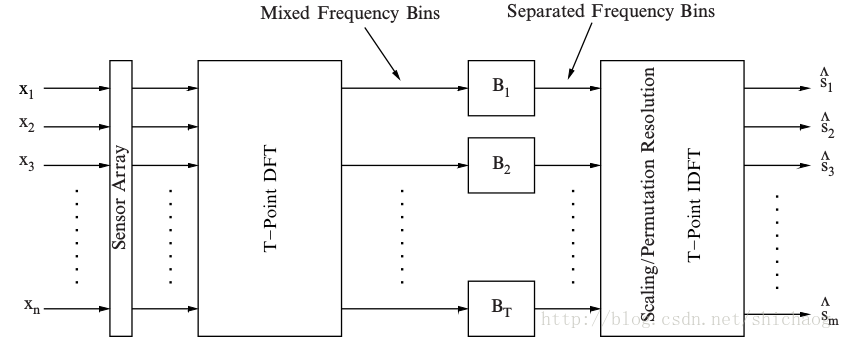
频域盲分离框图
分离准则
盲源分离方法建立在对声源和混合矩阵的不同假设的基础上,一般声源是独立的,至少是不相关的。分离的判决准则可以分为两类,一类是基于高阶统计量(HOS,higher-order statics),和二阶统计量(SOS,second-order statics)。N表示声源数,M表示麦克风数。这在后文一个实例中使用到这一准则。
| 子空间方法 | 二阶或者三阶累积量 | 非静态,列优先,互质 |
| 降到瞬时混合情况求解 | 1.SOS/HOS对于2*2系统 2.独立功率谱 3.累计量的书序大于二,ML准则 | 互累计量,时频域稀疏 |
卷积盲源分离频域法
卷积盲源分离包括两类主要方法:时域和频域。设是N个源信号。是第个麦克风从第个声源在卷积模型下的观察的信号值。
其中是时间的离散表示,h_{jk}是声源k到麦克风的脉冲响应。假设N个声源,则有:
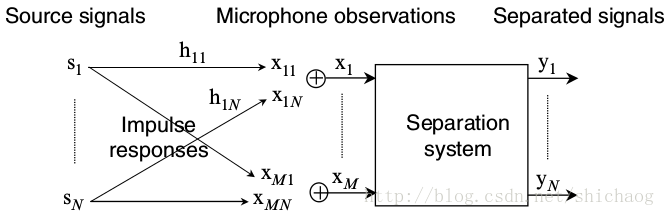
对分离效果的好坏使用信号/干扰比(signal-to-interference ratio, SIR)和信号/失真比(signal-to-distortion ratio)。
(dB)
(dB)
是在输出端的部分。
SDR定义如下:
失真定义于分母,这通过找到合适的幅度调节因子和时间调节因子最小化失真获得SDR。最优通过最大化互相关获得:
通过最小均方误差获得:

通过STFT将每一个麦克风观察到的时域信号转换到频域时间信号: 每一个离散的频点。分析用的窗函数可以使用汉宁窗。如果帧长能够包括绝大部分的脉冲响应$h_{jk}$,则卷积模型可近似使用瞬时模型近似: 则有: 向量表示如下: 接下来的操作,分离,置换以及缩放和T-F掩码都在频域做。复共轭矩阵的关系如下: 这里最关键的就是求分离矩阵,这个非常类似AEC情况下的回声消除求权重的过程,由于AEC是一维,BSS是多维且矩阵间互相影响,所以其计算特别耗时。 但是这时可以利用声源定位技术,在大概知道多个声源的方向,这时分离矩阵的系数应该让各个方向上能量和其它方向上的能量比值最大。 另外针对也许特殊的场景,不放考虑使用DNN方式,先前训练好几组权重系数。 这里给出一个matlab版本程序,需要说明的是,这个程序在无背景噪声,线阵,麦克风大间距下效果非常明显。
T-F(Time-Frequency)
利用信号的稀疏性(对每一个时频点,都只有一个信号占绝大部分),通过对信号时频域加掩码的方式抑制信号,这样可以将视频点分成N个类,每个类对应于一个声源,这个方法的一个典型是DUET(Degenerate Unmixing Estimation Technique)。
1.对原始信号做STFT 2.特征提取,根据STFT后的频点选择特征,,大多数这类方法选择,幅度比和相位差做为特性。 3.聚类,如k-means方法。 4.分离,
本章小节
本章主要介绍了声源分离技术的原理,阐述了在beamformering技术中,相关参数设置对波束形成方向图的影响,也介绍了几种常见的beamformer技术,而后有介绍了基于盲源分离方法.这是后续实例章节的理论基础。