第二十八章 语音识别概述
语音识别问题就是模式分类问题。
一个基本的语音识别系统如下图,实线是识别过程,虚线是模型训练部分(声学模型,字典和语言模型)。
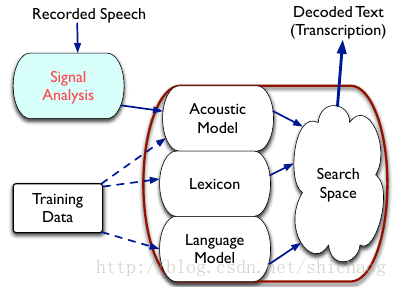
语音识别是把语音声波转换成文字。人耳的听觉范围约50Hz~20KHz,人发声的频率范围约85Hz~8KHz,当前语音识别系统绝大多数采样16kHz采样率,16bits位宽进行识别。这就是一个宽带(可以含的信息量大)信号处理。原始语音数据量还是很大的。
- 信号处理主要用于声学特征提取,声学模型可以根据该特征计算声学单元各成分的概率,对于基于深度学习的方法则可以直接有声学特征到文字(声学打分含在深度学习的隐藏层中),在日常的嘈杂环境中,信号处理还被用于语音增强,这包括回声消除,主动降噪,波束形成,去混响等等。
- 声学模型,通常一个字的发音分为多个音节,每个音节又分为若干音素,不同的字是不同音节的有序组合,不同的音节又是不同音素的有序组合,这些有序组合通常使用马尔科夫链来表示,在实际工程计算中使用加权有限自动机wfst来表示。特征常用的有LPC,MFCC,在深度学习方法之后也可以采用logFbank做为特征,这在减少计算量的同时,以类似人耳的方式对音频进行了处理,以获得较好的语音识别性能。
- 发音词典,包含了语音识别系统能够处理的所有词汇及其发音,发音字典建立了声学模型单元和语言模型单元间的映射关系。
- 语言模型,语言模型是对人类说话习惯性的描述,如"请关门"和"请关闷",如果给发音”qing guan men“,那么绝大多数人会认为是请关门,语言模型通常基于统计的N元文法及其变体。
- 解码器,解码器是语音识别系统的核心之一,其根据输入的信号,根据声学特征,语言模型以及发音词典寻找最大概率的词串。
- 开源语音识别框架,kaldi用的较为广泛,且kaldi已经支持开源深度学习框架tensorflow,未来将会更加完善,搭建一个demo级别的语音识别系统将轻轻松松。一个语音识别系统的准确率将取决于训练的语料集和文本集合。
识别器特征选取
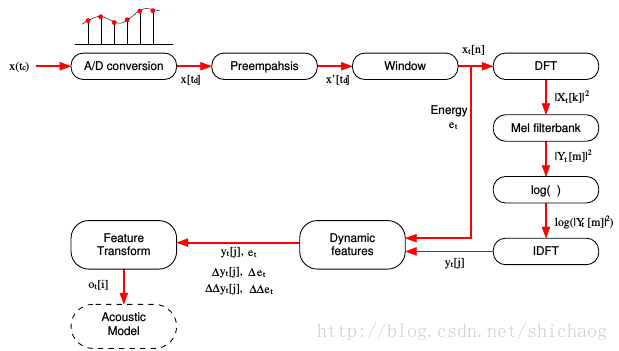
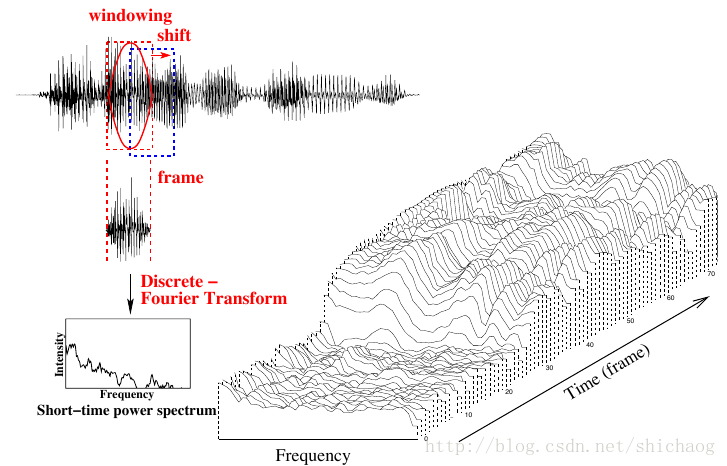
一个字持续了200ms~300ms(3200~4800点),这个数据量还是比较大的,我们期望减小数据处理量能够小一些,这就需要从上面(3200~4800)数据点提取出能正确识别的语音信息,这就要求降维后的信息能够正确表示语音,且背景噪声以及说话语速等影响化。 为了实现降维通常会采用STFT(短时傅里叶变换),之所以短时是因为对原始语音进行了加窗,因为语音可以看成是短时(10~30ms)平稳信号,当前大多数语音识别系统都是按25ms加窗(400采样点)做512点(512维)FFT。用傅里叶变换将声波变换成频谱和幅度。 但是FFT之后的数据维度依然很高,通常这是会log-mel特征(40+维,根据人耳对频点的灵敏性)做为神经网络的输入特征(维度从512将到了40+维).log-mel特征有些文献称为logfbank(log filter bank, 从图16.3可以看到很多l滤波器组)。
但是logfbank对于传统的高斯混合统计模型而言,维度还是多了,在做EM时不宜调节,所以又对og fbank做了梅尔导谱系数(MFCC, Mel Frequency Cepstral Coefficients),后进行DCT变换得到(13+维)特征,并不直接取DCT变换后的个频谱分量,而是采用和“梅尔”缩放一样的粒度对DCT后的频谱取三角窗平均;通常也会采取预加重技术抵消加窗带来的影响。对信号加噪。高斯混合模型通常使用13维的MFCC系数(也有使用PLP, 相对频谱变换-感知线性预测, perceptual linear prediction做为特征的),也有DNN也使用MFCC做为特征输入(但是现在很少了)。为了不丢失动态性,通常还会对MFCC做一阶和二阶微分获得总共39为的特征(有可能也会加上pitch,能量等)做为最终特征。 总结来说: 对于ASR,常用的特征是FBANK,MFCCs以及PLP特征。
- 特征应该包括足够的信息以区分音素(好的时间分辨率10ms,好的频率分辨率20~40ms)
- 独立于基频和其谐波
- 对不同的说话人要有鲁棒性
- 对噪声和通道失真要有鲁棒性
- 具有好的模型匹配特征(特征维度尽量低,对于GMM还要求特征之间独立,对于NN方法则无此要求)
预加重模块增加了高频语音信号的幅度,预加重公式如下:
语音信号是非稳态信号,但是信号处理的算法通常认为信号是稳态的,通常加窗以获得短时平稳信号:
即
为了减小截断带来的影响,通常使用hanning或者hamming窗
音素
有了特征之后就是如何使用这些特征,对于"中"这个字,可将其区分/ZH/ /ON/ /G/这三个发音单元,这样这样如果前一节的特征能够按顺序匹配上这三个音素,那么可以认为说话人极有可能说了这个单词,在音素层级的识别时,会将上述的音素映射成HMM状态(映射成0,1,...的数字序列),使用有限状态转换器去做匹配的动作。这在第十三章kaldi入门是可以看到这一过程的。当然后面也有基于三音素,字符层级和单词级别(罕见词难处理)甚至是句子级别的识别,这取决于数据集和任务以及可用资源。
- 上下文依赖的音素聚类
当使用上下文依赖的关系时,可以提高识别率,但是带来音素组合比较多,如果有42个音素,采用三状态的组合,那么每次要计算概率的计算量太大,实际中采用聚类的方式,将相近和相似的组合合并成一个组合,以减小决策树的规模。
语音识别概率模型
将音素以及音素序列用离散的类来模拟。语音识别的目标是预测正确的类序列。如果表示从声波提取的特征向量序列,那么语音识别系统可以根据最优分类方程来工作:
实际上使用贝叶斯准则来计算该值。
其中是声学似然(声学打分),代表了词被说了的情况下,语音序列出现的概率。是语音打分,是语音序列出现的先验概率,其计算依赖于语言模型,在忽略语音序列出现概率的情况下,上式可以简化为:
这样语音识别可以分为两个主要步骤,特征提取和解码。 ASR主要包括四个部分:信号处理和特征提取,声学模型(AM,acoustic model),语言模型(LM,language model)和解码搜索(hypothesis search)。
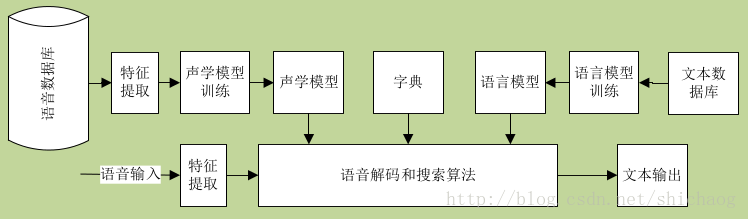
总结来说语音识别过程首先是将麦克风采集到的数据进行特征提取,然后根据声学模型和发音字典使用决策树搜索输入特征序列对应的字或词,最后根据语言模型(如"中心"和"忠心"在不同语义中使用)来确定输入特征对应的字或者词。
声学模型
声学模型使用GMM-HMM(混合高斯-隐马尔科夫模型,Gaussian mixture model-HMM),训练该模型的准则有早期的最大似然准则(ML,maximum likelihood),中期的序列判别训练法(sequence hierarchical model),以及目前广泛使用的给予deep learning的特征学习法:深度神经元网络(Deep Neural Network DNN)。
GMM模型
用在说话人识别,语音特性降噪以及语音识别方面。 若随机变量服从均值为,,方差为的概率分布,则其概率密度函数是:
则称服从高斯分布(正态分布)。记作:
正态随机向量的高斯分布是:
记作:,其中是维协方差矩阵,是的行列式,。 一个连续标量$X$的混合高斯分布的概率密度函数:
混合权重的累加和等于一,即和单高斯分布相比,上式是一个具有多个峰值分布(混合高斯分布),体现在。混合高斯分布随机变量的期望是 多元混合高斯分布的联合概率密度函数是:
参数估计
对于多元混合高斯分布,参数变量,这里参数估计的目标是选择合适的参数以使混合高斯模型符合建立的语音模型。 使用最大似然估计法估计混合高斯分布的参数:
后验概率$h$的计算如下:
基于当前(第j次)的参数估计,的条件概率取决于每一个采样。 GMM模型适合用来对语音特征建模,而现实世界中组成的字的音节所包含的语音特征是有顺序概念在里面的,这时使用HMM来表示其次序特征。 GMM模型不能有效的对呈非线性或者近似线性的数据进行建模。
隐马尔科夫模型HMM(hidden markov model)
HMM,的核心就是状态的概念,状态本身是离散的随机变量,用于描述随机过程。
马尔科夫链
设马尔科夫链的状态空间是,一个马尔科夫链,可被转移概率完全表示,定义如下:
如果转移概率和时间无关,则得到齐次马尔科夫链,其矩阵表示方式如下:
其观察概率分布,观察向量是离散的,每个状态对应的概率分布用来描述观察的概率:
在语音识别中,使用HMM的概率密度函数来描述观察向量的概率分布,其概率密度函数在语音识别中选择GMM的概率密度函数:
隐马尔科夫模型是统计模型,其被用来描述一个含有隐含位置参数的马尔科夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来进一步的分析。例如模式识别。
隐马尔科夫模型
其是序列的概率模型,在每一个时刻都有一个状态与之对应。计算$p(sequence|model)$包括以对指数状态序列求和。可以使用动态规划递归求解,模型参数训练的目标是最大化训练数据集的概率。 其涉及两个重要的算法
- 前向后向算法 递归计算状态概率,在模型训练时使用。
- 维特比算法 对于给定的字符序列,查找到最有可能的HMM状态序列。 早期基于HMM的语言模型使用向量量化(Vector Quantization)将语音特征映射到一个符号(通常有256个符号),每一个发音由三个马尔科夫状态表示,也就是三音素模型。
HMM参数学习-Baum-Welch法
定义“完整的数据”为,其中是观测值(如语音特征)。是隐藏随机变量(如非观测的HMM状态序列),这里要解决的是对未知模型参数的估计,这通过最大化对数似然度可以求得,然而直接求解不易。可转换为如下公式求的估计:
其中是前一次的估计。则上式离散情况下的期望值如下:
为了计算的方便,将数据集改为,依然是观测序列,是观测状态序列,是马尔科夫链状态序列,BaTum-Welch算法中需要在E步骤中计算得到如下的条件期望值,或成为辅助函数:
这里期望通过隐藏状态序列确定得到。
维特比算法
在给定观察序列的情况下,如何高效的找到最优的HMM状态序列。动态规划算法用于解决这类阶路劲最优化的问题被称为维特比(Viterbi)算法。对于转移状态给定的HMM,设状态输出概率分布为,令表示部分观察序列到达时间,同时相应的HMM状态序列在该时间处在状态时的联合似然度的最大值:
对于最终阶段,有最优函数,这通过计算所有的阶段来得到。当前处理阶段的局部最优似然度,可以使用下面的函数等式来进行递归得到:
在语音建模和相关语音识别应用中一个最有趣且特别的问题就是声学特征序列的长度可变性。
HMM识别器
单词序列被分解为基音序列。在已知单词序列下观察到特征序列的概率按如下公式计算:
是单词发音序列,每一个序列有事基音的序列,则有:
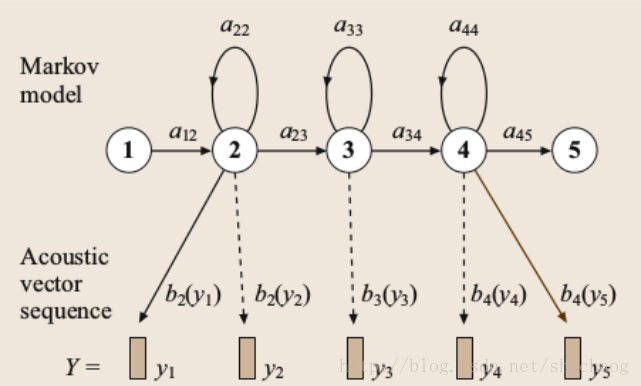
图16.8基于HMM的音素模型
如上图所示,基音由隐马尔科夫密度表示,状态转移参数是,观察分布是,其通常是混合高斯分布:
其中是均值为,方差为,约10到20维的联合高斯分布。由于声学向量维度较高,协方差矩阵通常限制为对角阵。状态进入和退出是非发散。是基音序列的线性组合,声学似然如下:
其中是混合模型的状态序列。
声学模型参数和可以使用期望最大化的方式从语料库中训练得到。 由于发音通常是上下文相关的,如food和cool,通常使用三音子模型,以实现上下文相关法。如果有N个基音。那么将有个可能的三音子。可以使用映射集群的方式缩减规模。 逻辑到物理模型集群通常是对状态层次的集聚而非模型层级的集群,每个状态所属的集群通过决策树确定。每个音素的状态位置有一个二进制决策树与之相关。每一个音素模型有三个状态,树的每个节点都是语义的判断。将由得到的逻辑模型音素的状态的集群。以最大化训练数据集的最终状态集概率为准则设置各个节点的判断条件。
语言模型
语言模型计算单词序列的概率,传统语言模型当前词的概率依赖前n个单词,这通常由马尔科夫过程描述。
N-gram语言模型
一个单词序列的概率由以下公式表示:
对于大词汇量的识别问题,第个单词的概率只依赖于前个。
通常N取2~4。通过计算训练数据集中N-gram出现的次数来形成最大似然概率。例如: 是三个词出现的次数,是出现的概率,则:
这种统计方式存在一个数据稀疏性问题。这通过结合非技术概率模型解决。
一元和二元语法模型的概率基于训练文集中单词出现的次数来统计。
其中是计数门限,是不连续系数,是归一化常数。 如果语音模型完全符合HMM模型(基于对角协方差多元高斯混合分布概率模型)假设的统计特性病切训练数据是充足的,那么就最小方差和零偏场景,最大似然准则解是最优解。可以从两个方面弥补非理想性,一个是参数估计策略,一个是模型。也有很多方法从这两个方面提升性能。
归一化
归一化的目的是减小环境和说话人物理特性差异的影响。由于前端特征源于对数频谱,特征值均值归一化见笑了通道的差异影响。倒谱方差归一化缩放每一个特征系数以获得单位方差,这减小了加性噪声的影响。 声道长度变化将导致共振峰频率近似线性变换,所以在前端特征提取时考虑线性缩放滤波器中心频率以获得近乎一致的共振峰频率,这一过程被称为VTLN(vocal-track-length normalization)。VTLN需要解决缩放函数定义和针对每个说话人的缩放函数参数估计。缩放函数可以采用分段线性函数(针对男声和女声所含信息不同)。 另外,如果训练语音数据集不能完全覆盖测试集中的说话人和说话场景,则语音识别将会产生错误,这类问题可以通过自适应的方法进行求解。
加权有限状态转换机的语音识别
这是传统的语音识别方法,包括HMM模型,文本相关模型,发音字典,统计语法,单词和音素格。
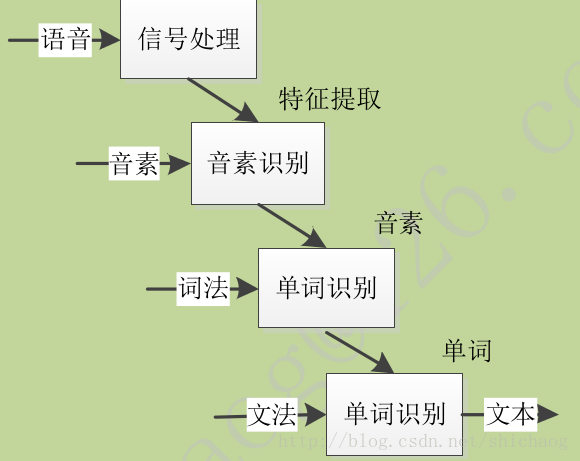
传统ASR流程
加权有限自动机
有限自动机定义为一个五元组:
其中是状态集合,是输入符号集合,为转移(边)集,其接收一个状态和输入符号,输出一个目的状态或者空。是初始状态,是最终状态集或者接受状态集。
权值的半环理论
语音识别时,不仅仅想要知道某个字串是否能够被接受,还要知道字串在语音中出现的概率。一个半环为一个五元组.
语音识别由早期的声学模型(单音素,三音素)+HMM+NGRAM组成识别系统,现在声学模型可以使用深度学习模型替代了,早期的声学模型基于DNN模型,后来由于语音其实是有上下文依赖关系存在的,深度学习单元又有LSTM出现,GRU实现类似的功能,但是计算量更少,训练过程中发现有些在一个长句子中,有些音素在根据发音字典解码成字占的比重比较大,又推出了Attention机制,不过,音素级别的训练需要大量的标注数据,所以呢,最早到2006年,就有文章提出来到字符和单词级别的识别,这就是端到端识别把从原始语音数据提取的特征编码成识别网络需要的编码格式,然后对这个编码进行前向计算,计算完了之后,计算完了之后在进行解码,解码的输出就是需要的字符或者单词。到2014年端到端识别又进行了改进,如加入了Attention机制。 ctc(connectionist temporal classification),不需要对齐 2014,2015两年,百度发表了deep speech,和deep speech2也是基于端到端的识别.
深度学习模型
- RNN (Robinson and Fallside, 1991)
- LSTM (Graves el al.2013)
- Deep LSTM-P Sak et al.(2014)
- CLDNN (Sainath et al. 2015a)
- GRU DeepSpeech (Amodei at el. 2015)
BLSTM(i-vector normalization) 2016
CTC sequence discriminative training sequence2sequence Watch Listen,
Raw waveform speech recognition CLDNN WaveNet-sytle CNN最早于98年提出来用于图像识别上,在语音识别上,CNN方法 可以利用时域和频域两个维度的相关性和信号时移不变性,通常CNN的层数不超过十几层,其后再加RNN和一层全连接层 ~2014年 深度学习成功用在提升ASR识别率上,RNN
~2015年
~2017(井喷)
- 基于多通道的深度学习处理方法 (个人觉得未来三年内会被广泛采用,也就是NN芯片出来两代的时间)paper1,paper2
- 混合型网络 如ResNet和LSTM结合pdf,ResNet和卷积CTC结合pdf
- 端到端 声学模型不仅仅是音素级别的了,可以是直接转换成字符或者单词.对于ASR,端到端模型常常采用CTC做为代价函数.腾讯的RCNN-CTC模型可以在WSJ和腾讯测试集WER比大部分现行的模型要低pdf,
- 减少训练时间 当前在训练参数时,采用的方法基本都是随机梯度法,要减小训练时间,总体上思路有两类,一类是充分发掘硬件的资源优势,一类是优化算法,减小计算量或者提高并发性,二者也不是完全割裂的; 对于充分发掘硬件资源,受限于板卡和主机之间通信延迟和batch size大小,基于cache特性减小训练时间也是一个方法,减小数据访问的开销,嵌入式端的本地识别和信号增强也有这个思路;Cache Based Recurrent Neural Network Language Model Inference for First Pass Speech Recognition 2014 对于算法层次,最基本的层次是网络模型的变更,如RNN到LSTM以及到GRU等. 硬件和算法资源相结合,一个是更另一个是更改loss函数,loss函数更改可以带来batch size的增加,这样可以充分利用服务器资源的同时也不会或者带来的损失很小.LARGE BATCH TRAINING OF CONVOLUTIONAL NETWORKS 2017 *训练和使用场景相结合
- 输入模型
输入的语音信号通常采用能量归一化,提取谱特征,对数压缩,以及特征维度的均值和方差归一化,对数谱在频带之间可以获得很高的动态范围,这也意味这一些频带在压缩中信息会丢失掉,PCEN 2016层较上述方法更优.
Reducing Bias in Production Speech Models 2017.
端到端语音识别