第二章 重采样原理及实现
重采样算法用于实现采样率转换的场景,源于硬件和算法两方面的需求,硬件方面主要是codec,存储,计算和传输等限制,在算法层次,云端ASR,AEC,编码解码中都有可能用到采样率转换,除此以外,在非同源时钟多通道场景,如AEC,beamforming也会用到重采样算法。
由于github等类似的网上有各种编程语言实现的开源的重采样源码,这里以原理为主.
信号重采样
假设信号是连续时间信号,则以为间隔对信号采样,采样后信号为,是整数, 是采样周期,根据奈奎斯特采样定理,当是带限信号,且其频带范围在之间,这时采样不会导致频谱混跌,采样率,设是的傅里叶变换,则有,可以假定:
根据香龙定理,由重构的公式如下:
其中,
以下讨论在(),仅讨论方程2.1是整数倍情况下的。
当新的采样率小于原始采样率时,低通滤波截止频率必须是新采样率的二分之一,即。对于理想的低通滤波器,则有:
公式的前面增益因子是为了保持通带内单位增益。
函数的波形如下:
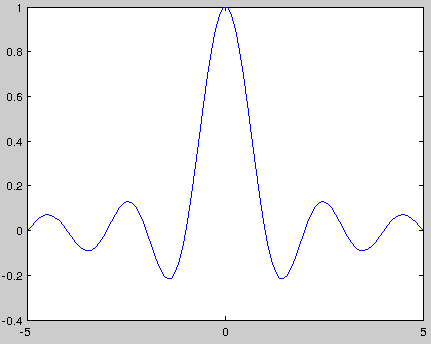
公式1用卷积公式表示为:。
该卷积过程可以看成是sinc函数的平移叠加,每个sinc函数对应于一个采样点,并且幅度被采样点调制过,所有sinc函数加在一起是原始信号。值为零的地方位于整数处(除)。这意味着时刻(对应于一个采样点),为和的唯一贡献是采样信号。
函数是理想低通滤波器,实际使用时会进行加窗处理。
音频重采样
音频应用有时遇到44.1kHz/48KHz/32kHz/16kHz以及8kHz之间互相转换,这一过程称为SRC(sample rate converter),产品上有用codec芯片硬件实现SRC功能,有用软件实现SRC。
采样率转换的基本思想是抽取和内插,从信号角度看音频重采样就是滤波。滤波函数的窗口大小以及插值函数一旦被确定,其重采样的性能也就确定了。
抽取可能引起频谱混叠,而内插会产生镜频分量。通常在抽取前先加抗混叠滤波器,在内插后加抗镜频滤波器,在语音识别里所需语音信号采样率由ASR(automatic speech recognition)声学模型输入特征决定的。
重采样过程
1.设音频信号的原始采样率是L,新的采样率是M,原始信号长度是N,则新采样率下信号的长度K满足如下关系:
2.对每个离散时间值:,则实际值的值为:
为在原始采样间隔的情况下,要进行插值的位置。
3.确定两个加权系数的值,利用第二步计算得到的值求两个权值。选择恰当的权值才能让线性差值所有插取的值更加接近插值点的理想幅度值。让和分别代表两个重采样权值。
- 根据两个权值,估计插入点的具体幅度值。
sinc重采样
开源语音处理算法speex使用了sinc函数方法,窗函数是凯撒窗。
以整数因子抽取(麦克风采样率为48KHz,ASR的声学特征提取信号的采样率是16KHz)为例来说明算法的实现过程。设是对模拟信号以奈奎斯特采样率采样得到的信号,其频谱为,则在频率区间(对应的模拟频率是),是非零的。现在按整数倍D对进行抽取。为了避免频谱混跌,必须先对进行抗混跌低通滤波,将的有效频带限制在折叠频率以内,等效的数字频率为弧度以内。
对按整数倍因子进行抽取,得到信号。其原理框图如下:
理想情况下,抗混叠低通滤波器的频率响应:
经过抗混叠低通滤波器后输出为:
如果为因果稳定系统,则式2.8中的卷积求和从0开始是成立的,按照整数被因子D对抽取后得到:
- 直接型FIR滤波器实现
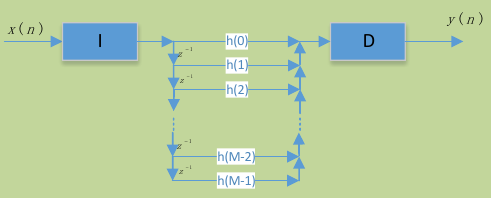
图3中的结构表示了式8的滤波过程,在经过抽取器D抽取相应的采样点,在表示的插值过程中,会牵涉到在相邻样本值之间插入个零值,如果值比较大,则进入FIR滤波器的信号大部分为零,因此乘法运算的结果大部分也是零,即多数乘法是无效的,因此这种运算效率是比较低的。
- 整数因子D抽取直接型FIR滤波器结构
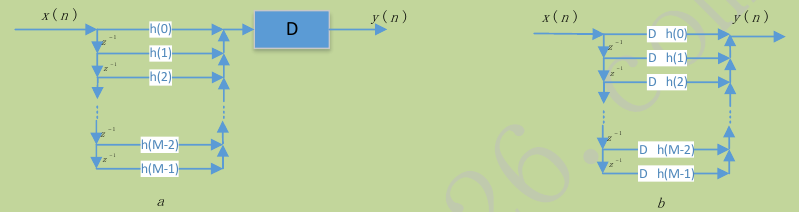
整数因子D抽取系统的直接型FIR滤波器结构如图4a所示,该结构中,FIR滤波器以最高采样率运行,但其输出的每D个样值中抽取一个做为最终输出,丢弃个样值,这样效率较低。
高效的FIR滤波器将抽取操作D嵌入FIR滤波器结构中,图4b所示,a的抽取器在时刻开通,选通FIR滤波器的每个输出做为抽取系统输出序列的一个样值。
b的抽取器在时刻同时开通,选通FIR滤波器输入信号的一组延迟:
,再进行乘法,加法运算,得到抽取系统输出序列的一个样值,,b的运算量仅是a的D分之一。
- 整数因子I内插系统直接型FIR滤波器结构
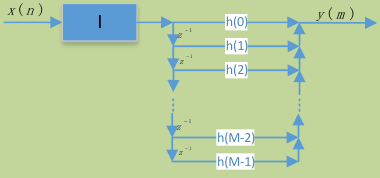
根据图5给出的结构,需要FIR滤波器以速度运行,该效率较低,较高实现效率如下6b。

多相滤波结构
这种结构是工程实现中用的多的一种结构,不仅仅是重采样用,在其它需要滤波的场合,使用该滤波器的频次都是比较高的。尤其是在ASIC电路设计上,可以使用几百KB大小存储空间的的低端CPLD实现多路麦克风数据的重采样,在一些集成电路中,也开始集成了这个硬件重采样,它们的滤波结构大部分也是采用这种结构。
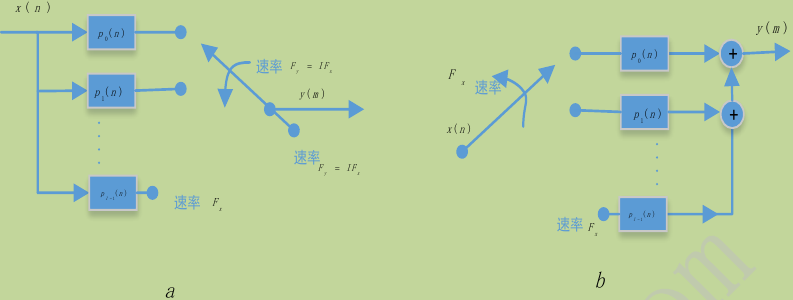
图7b的实现结构使用较短的多相滤波器组来实现内插功能,如果滤波器的总长度为,则多相滤波器组有个长度为的短滤波器构成,且个短滤波器轮流分时工作,所以称之为多相滤波器。整数因子I内插系统直接型FIR滤波器的输出。零值内插器的输出序列是在输入序列的两个相邻样值之间插入个零样值得到,因此进入FIR滤波器的M个样值中只有个非零值.即在任意时刻m,计算时只有N个非零值与中的N个系数相乘。
所以,有,当时,有:
上时中看做长度的子滤波器的单位脉冲响应,并用表示,则:
这样,从开始,整数因子内插系统的输出序列计算如下:
当从零开始增大时,k从0开始以I为周期循环取值,j表示循环周期数。所以式2.12对应的多相滤波器的结构如图2.8所示。输出序列就是序列就是从开始,依次循环选取I个子滤波器输出所形成的序列。多相滤波器的单位脉冲响应为:
式中,为的长度.一般选择抗混叠FIR滤波器总长度, 。电子开关以速率逆时针旋转,从子滤波器在时刻开始,并输出;然后电子开关以速率逆时针旋转一周,即每次转到子滤波器时,输出端就以速率送出一个样值。从频域角度看,线性重采样适合应用于下采样,有些场景需要先升采样,然后再降采样以提高精度,如将44.1kHz的蓝牙语音信号转换成16KHz的信号,为了减少SRC带来的失真,通常会将44.1KHz信号先升采样到和16KHz的一个公倍数,然后再进行整数倍抽取。
MATLAB实现
开源的c/c++重采样代码很多,这里以MATLAB结合绘图,以便有一个直观的对这一过程有个了解。下图是将48KHz信号重采样到16KHz,并绘制了它们的频谱如下:
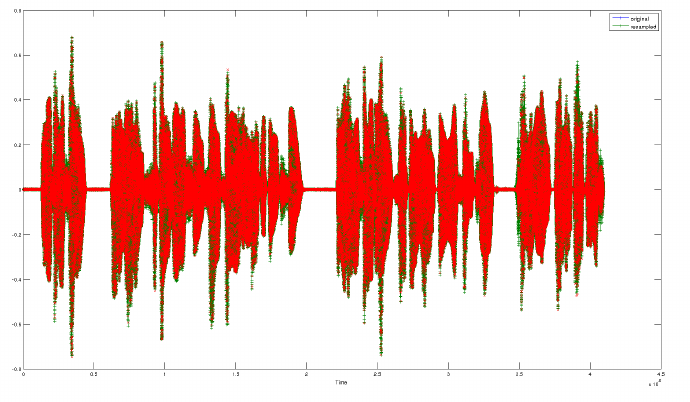
上图是同一段语音48KHz和16KHz绘制的重叠图,可以看到在包络上“沙沙的背影”还是有些差异,这些差异是重采样非理想性带来的。
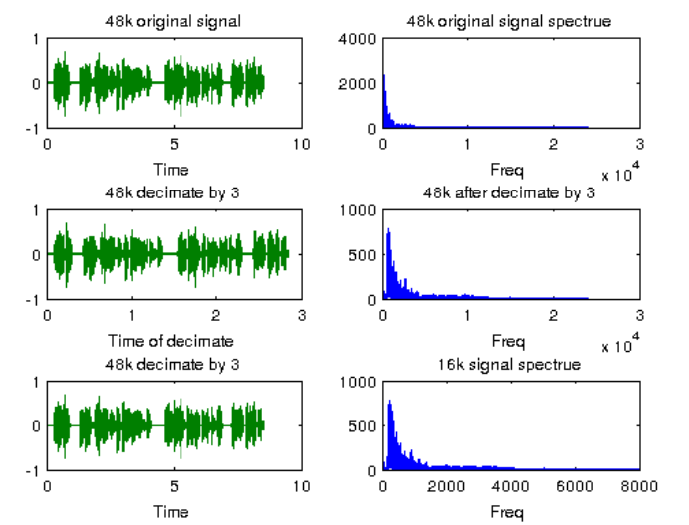
图2.10的第一行是原始48KHz信号的时域和频域波形图,其频域波形在24KHz截止,第二行是48KHz采样率下抽取后信号的时域和频域波形,对于第一行和第二行来看,频谱差异还是比较容易看出来的,第三行是16KHz采样率下绘制的重采样后的时域和频域波形,其截止频率在8KHz,和第二行的信号频率差异性较小。上述示例的MATKAB代码如下:
clear; close all; clc;
%read sound wave
[x,fs]=audioread('48k_sound.wav');
% sound(x,48000);
%sound(y,fs,nbits);
N=length(x);
tx=(0:N-1)/fs;%calc the time that correspond to original signal
xf=fft(x);
fx=(0:N/2)*fs/N;
figure(1);
subplot(321);plot(tx,x);xlabel('Time');title('48k original signal');
subplot(322);plot(fx,abs(xf(1:N/2+1)));xlabel('Freq ');title('48k original signal spectrue');
audiowrite('48k_sound.wav',x,48000);
%decimate signal
k=1:N/3;% Number to decimate 48k to 16k
%filter design kasier
fp=8000;fc=12000;as=100;ap=1;FS=48000;
wc=2*fc/FS; wp=2*fp/FS;%kaiser window
N=ceil((as-7.95)/(14.36*(wc-wp)/2))+1;
beta=0.1102*(as-8.7);
win=kaiser(N+1, beta);
wvtool(win);
B=fir1(N, wc,win);
freqz(B,1,512,fs);
y=filter(B,1,x)
y=downsample(y,3);
%实际上这里是每隔三个点取一个点,即先低通滤波再取点,和紧接着的下面的三行结果是一样的
% y=x(3*k);% 48k--->16k,and data store in y
%y=decimate(x,1,3);
% y=resample(x,1,3);
M=length(y);% M is the length of y
%analysis y under the frequency of 48k
ty=(0:M-1)/fs; %fs equ 48k
subplot(323);plot(ty,y);xlabel('Time of decimate');title('48k decimate by 3');
yf=fft(y);% fft of 48k downsample by 3
fy=(0:M/2)*fs/M;
subplot(324);plot(fy,abs(yf(1:M/2+1)));xlabel('Freq');title('48k after decimate by 3');
%decimate data under sample 16k
tz=(0:M-1)/(fs/3);
subplot(325);plot(tz,y);xlabel('Time');title('48k decimate by 3');
fz=(0:M/2)*(fs/3)/M;
subplot(326);plot(fz,abs(yf(1:M/2+1)));xlabel('Freq ');title('16k signal spectrue');
sound(y,16000);
audiowrite('16k_sound.wav',y,16000);
% %ellipord
% fp=8000;fc=12000;as=100;ap=1;fs=48000;
% wc=2*fc/fs;wp=2*fp/fs;
% [n,wn]=ellipord(wp,wc,ap,as);%
% [b,a]=ellip(n,ap,as,wn);
% freqz(b,a,512,fs);
重采样性能评估
音频信号的好坏常采用信噪比来评估,同样可以根据重采样后音频信号的信噪比来评估重采样的质量。信噪比的定义如下:
式中,为原始信号,是转换后的同频率音频信号,M为音频信号的长度。信噪比越大意味着总体上原始音频信号和重采样后的信号之间的差距较小。接近的程度越高。在功放的测试中就有信噪比这么一项。
由于语音信号是短时平稳(10ms~30ms),可以将语音信号分帧计算各帧的信噪比,平均后得到信噪比。
由于ASR对频谱比较敏感,这和特征提取有关,还需要知道信号频域的失真情况。这通过对原始语音和resample后的语音做STFT后,插值后,根据频谱绘制每一个频点的差异,这样可以看到resample对个别频点的影响是否可以接受。
结束语
本章主要给出来重采样的原理和其理论实现方法,并讲述了在实际的智能设备中使用重采样的场景,并给出了重采样的高效实现方法,这对RTL级(register translation level)是有益的,对做ASIC是可以用上的,最后也给出了评判重采样后信号质量好坏的方法。