第十八章 语音编解码
对时效性有要求的声音/语音进行远距离传输,考虑到其受传输通道带宽和可靠性制约,需要对声音进行编解码。
在选取语音编码器需要考虑如下部分:
- 失真尽量小;
- 在特定语音质量下,比特率要尽量低;
- 延迟应当尽量下,即时通讯的基本要求;
- 传输中的错包丢包;
vocoder
Vocoder声码器是用于语音信号的分析和合成的编解码器,其主要应用场景是语音压缩、合成、加密和传输。 发生时,气流经过喉头形成声源信号,然后经过由口,鼻腔和舌头构成的声道,声带震动产生浊音,不震动产生清音,声带震动产生基频。
对信号在频域进行分析,鉴别清浊音,测定浊音基频,进而选取清浊音判断; 在时域进行分析,利用周期性,可以提取一些参数进行线性预测,以及对信号做相关分析;
声码器主要分为:通道声码器,共振峰声码器,图案声码器,线性预测声码器、相关声码器和正交函数声码器。
相位声码器(phase vocoder)是使用相位信息对语音时域和频域进行缩放的一类声码器。
Pitch 音高/音调,人耳对声音调子高低的主观感受,音高的大小主要取决于声波基频F0的高低,频率高则音调高,反之则低,用Hz表示。
tone音色/音品,由声音波形的谐波频谱和包络决定。双二阶滤波器,其传递函数,是二阶IIR滤波器,含两个零点和两个极点,高阶滤波器对系数更为敏感,12dB/octave双二阶滤波器可用于音调tone控制;
白化和包络
 加窗对时域信号有淡入淡出功能,减少了谱泄漏,这可以通过看谱的频域波形获得。有很多的窗函数可以选择,不同的窗函数的主瓣宽度和旁瓣抑制能力不一样。
加窗对时域信号有淡入淡出功能,减少了谱泄漏,这可以通过看谱的频域波形获得。有很多的窗函数可以选择,不同的窗函数的主瓣宽度和旁瓣抑制能力不一样。

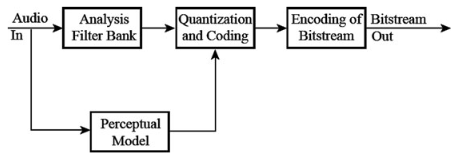
SILK编解码
silk是基于包传递方式的实时语音编解码器,支持四种采样率的编码。通过比特率控制,分包率,抗丢包以及非连续传输(discontinuous transmission DTX)来处理网络带宽,抖动,延迟,丢包的不利影响。并且SILK还提供编码复杂度参数,复杂度参数越高,编码的语音质量越高,需要处理器的能力越强。
在网络语音通信场景,网络上传输语音包的比特率是一定的,在一定的比特率下,编码器编码出的语音信号质量应当尽量高,而当前网络可用的比特率是可以估计出来的(图像占用了大部分的带宽,需要合理的分配)。
SILK编码控制参数
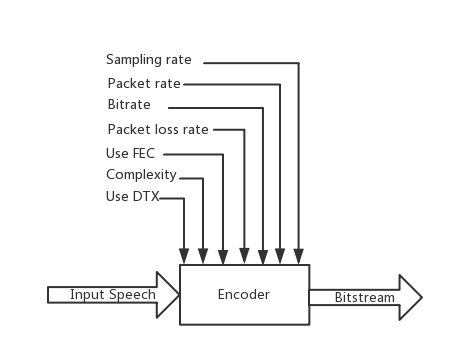
图1: SILK编码控制参数
Sampling rate分为四种
Narrowband(NB),8kHz采样率;
Mediumband(MB), 8或者12kHz;
Wideband(WB):8, 12或者16kHz采样率;
Super Wideband(SWB):8,12,16或者24kHz采样率。分包率
SILK以20ms为一帧进行编码,以1,2,3,4,或者5帧作为网络传输的一次有效载荷。由于传输时IP/UDP以及RTP头的开销,单位时间发送的包越少虽然减少了比特率,但延迟和丢包影响均变大。比特率
比特率可以设置成6~40kbps。更高的比特率可以减少量化噪声的影响,因此可以获得更高的语音质量。抗丢包率
使用帧间互相关减少比特率但这会让编码误差向后传递。使用FEC
其主要目的是对抗丢包,FEC\(in-band Forward Error Correction\)将语音起始\(onset\)或\(transient\)这些关键帧被再次以低比特率进行编码和传输。复杂度
复杂度分为高,中和低三种,其控制了编码的如下关键模块:
a) pitch分析中用到的白化滤波器阶数和下采样的质量
b)噪声包络估计中滤波器的阶数
c)延迟决策量化模块的残差信号状态数量。
d)多阶段LSF向量量化
- 使用DTX
Discontinuous Transmission(DTX)在安静和只有背景噪声语音段减少比特率。当DTX使能时,每400ms只有一帧被编码。
编码器组成
···
+---+
+----------------------------->| |
+---------+ | +---------+ | |
|Voice | | |LTP | | |
+----->|Activity |-----+ +---->|Scaling |---------+--->| |
| |Detector | 3 | | |Control |<+ 12 | | |
| +---------+ | | +---------+ | | | |
| | | +---------+ | | | |
| | | |Gains | | 11 | | |
| | | +->|Processor|-|---+---|--->| R |
| | | | | | | | | | a |
| \/ | | +---------+ | | | | n |
| +---------+ | | +---------+ | | | | g |
| |Pitch | | | |LSF | | | | | e |
| +->|Analysis |-+ | |Quantizer|-|---|---|--->| |
| | | |4| | | | | 8 | | | E |->
| | +---------+ | | +---------+ | | | | n |14
| | | | 9/\ 10| | | | | c |
| | | | | \/ | | | | o |
| | +---------+ | | +----------+| | | | d |
| | |Noise | +--|->|Prediction|+---|---|--->| e |
| +->|Shaping |-|--+ |Analysis || 7 | | | r |
| | |Analysis |5| | | || | | | |
| | +---------+ | | +----------+| | | | |
| | | | /\ | | | | |
| | +---------|--|-------+ | | | | |
| | | \/ \/ \/ \/ \/ | |
| +---------+ | | +---------+ +------------+ | |
| |High-Pass| | | | | |Noise | | |
-->|Filter |-+----+----->|Prefilter|------>|Shaping |->| |
1 | | 2 | | 6 |Quantization|13| |
+---------+ +---------+ +------------+ +---+
```
1是输入信号,2是高通滤波后的信号,3是语音检测估计,4是pitch lag/5ms以及语音判决/20ms,5是噪声包络估计系数,6经过分析噪声包络滤波器滤波后的输入语音信号,7 LPC的短时(5ms)和长时(20ms)的估计,8 LSF量化指数,9 LSF系数,10 LSF系数量化, 11 处理后增益值,综合噪声包络系数, 12 LTP状态缩放系数,在控制误差传播和预测增益这两者之间找最优,13 量化后信号, 14距离编码比特流。
VAD模块
该模块计算了每帧(20ms)语音的语音存在概率,tilt(权重信噪比)和SNR,计算过程采用了half-bank和QMF以及prototype滤波器将输入语音分成4个语音子带进行,分别是,对每个子带进行背景噪声估计跟踪,计算每个子带的平滑SNR,子带间的平均信噪比,语音概率。
High Pass filter
由于正常的语音信号低于60Hz基本是不会由人声的,所以为了减少干扰,使用了截至频率约在70Hz的高通滤波器对信号进行先处理,对于音乐信号,70Hz以下是存在有用信号的,使用了二阶自回归平滑ARMA(Auto Regressive Moving Average)滤波器实现。
Pitch 分析
pitch(基音)是人耳感知到的发音基频(F0),即声带振动的频率。是人耳听到的音调高低。

pitch估计
pitch估计首先区分是语音还是非语音,对于语音段,每帧计算4个基音周期(每5ms一个)。基音的相关性体现了信号的周期性。输入信号首先经过LP(Linear Prediction)白化滤波器白化,滤波器的牺牲由LPC(Linear Prediction Coding)分析获得。低中高三种复杂度的LPC的系数分别是8,12和16,复杂度越高的白化效果越好。白化后的信号用于寻找基音周期(也就是时域相关极大值的位置)。为了减少c代码实现中定点化带来的误差,使用reflection系数代替了LPC系数的直接计算。
噪声形状估计
噪声形状分析首先计算预滤波和噪声谱包络增益和滤波器量化系数。

噪声包络和频谱去加重示例
原始信号频谱(1)在去加重和谱峰匹配后,谱谷变得更低(2),量化噪声谱(3)基本和输入谱一致,码输入信号1编码比特率下边界和2 3之间的面积差成正比。 输入信号和去加重信号之间的传递函数是:
是去加重滤波器,包括短时滤波和尝试滤波部分,L是基音周期,d是滤波器的阶数。
预滤波
使用前一节估计到的系数对信号进行去加重。
预测分析
根据基音分析是否是语音做相应的处理。输入信号是基音分析白化之后的信号。
- 对于语音段,白化后的信号基音仍然占主要部分。进一步白化可以在相同的比特率下获得更高的语音质量,这可以通过对4个子帧使用长时预测分析LTP(Long-Term Prediction)。LTP系数用来估计残差信号,该残差信号是LPC分析模块输入,使用Burgs方法计算LPC系数,该系数使用被转换成LSF(Line Spectral Frequency)向量。对LSF进行量化,量化后的被转换为LPC系数,这样编解码器之间是完全同步的。LPC和LTP洗刷刷用于对输入信号进行高通滤波以及计算四个子带的残差信号能量。
- 对于非语音段,由于没有基音,分段内不存在基音周期,不需要进行LTP滤波,所以不使用白化后的信号,而是直接用Burgs方法计算高通滤波后的信号的LPC系数,将LPC系数转换成LSF向量,对LSF向量进行量化,然后将量化后的LSF向量转换成量化版的LPC系数。使用量化后的LPC系数对高通滤波的信号进行滤波并且计算4个子帧的残差信号的能量。
LSF量化
量化的主要目的是减少比特率,代价是引起失真,比特率越高失真越小,反之失真越大。常用的方法是使用定比特率的量化方法,即在比特率一定下使量化误差最小。
- 比特率和失真率的优化, 不使用权重比特率和失真率的目标函数最小化来求解,而是通过比特率码本方式。
- 误差映射,谱失真的估计不在LSF域进行,而是通过对误差向量的每个元素赋予一个独立的权重来估计,使用IHMW方法(Inverse Harmonic Mean Weighting)方法来计算权重向量,则目标函数变为:
其中是量化向量,LSF是输入待量化向量,C是量化的LSF向量,c从码本获得。
- 多级向量码本,memory使用效率高,在第一阶段是待量化的LSF向量,之后的每一级输入是前级输出量化误差。

- 码本离线训练,多级码本的码表需要离线使用大量数据训练得到。
LTP量化
对于语音帧,对于每个子帧预测分析得到5个LTP系数和4个权重矩阵。LTP系数使用熵约束向量量化。总共三个向量码本可用于量化,它们比特率-失真率不同。三个码本分别有10,20和40个向量,每个向量的比特数分别是3,4,5。给定权重矩阵和LTP向量,对于给定的码表和比特率,其加权比特率-失真率是:
u是比特率-失真率之间平衡的固定参数。
噪声包络量化
预滤波输出的信号在噪声包络分析中先乘以补偿增益,然后用综合包络滤波器和预测滤波器的差值或得残差信号。
距离编码
常用方法。
LPC综合
短时互相关在LPC分析滤波器中被去除了,在综合滤波器中再次得到。
是解码输出信号。
解码
在接收端,接收到的数据包被距离解码成若干帧。每个数据包解码后的若干帧包含了重构20ms语音帧的必要信息。
解码模块

包括: 1: 距离编码比特流 2:编码参数 3:脉冲和增益 4:基音周期和LTP系数 5:LPC系数 6:解码得到的信号
- 距离解码,该模块输出包括输入信号的脉冲,增益,LTP和LSF码表索引信息,这些信息用于后续解码LTP和LPC系数。
- 解码参数,当语音帧被解码时,对于每个子帧使用码表对LTP系数进行解码,LPC系数从LSF码表获得。
- 产生激励,脉冲信号乘以量化增益以产生激励信号。
- LTP综合,对于语音信号,激励信号被输入到LTP综合滤波器,这将产生长时互相关信息和LPC激励信号 。
使用基音周期L以及LTP解码系数。对于非语音信号,输出信号就是激励信号。
Opus编解码
Opus可以适用的范围很广,适用于低带宽应用一直到CD级别的应用。Opus是SILK和CELT编解码器的结合。可以根据网络情况动态更改比特率。Opus采用线性预测(Linear Prediction LP)和改进的离散余弦变换(Modified Discrete Transform MDCT)对语音和音乐获得好的压缩率。
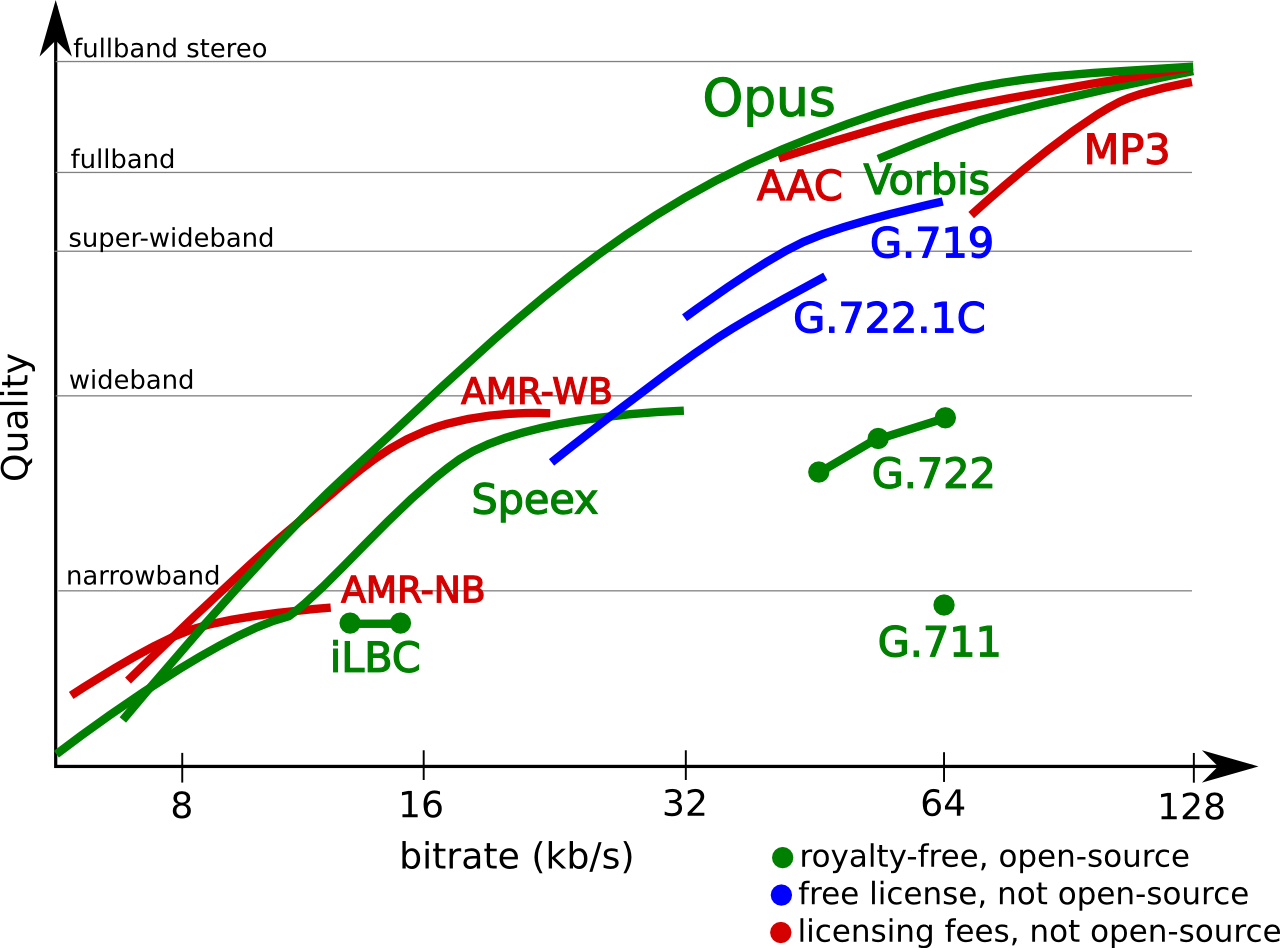
Opus是有损的,对于无损场景可以适用FLAC,超低比特率适用codec2.
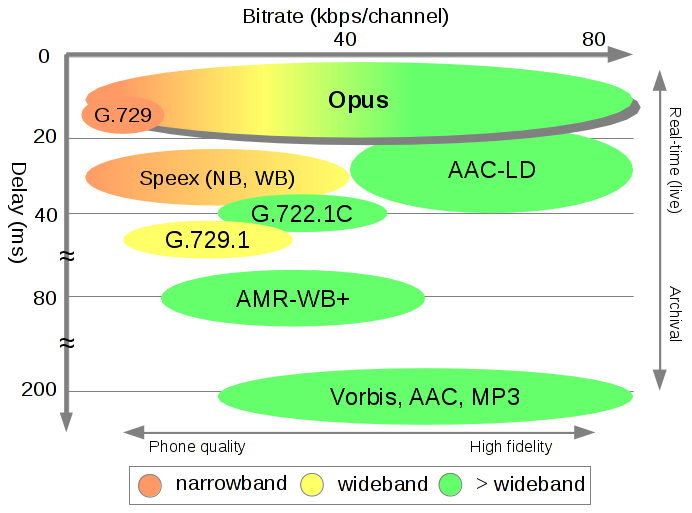
Opus1.3特性:
- 比特率从6kb/s~510kb/s
- 采样率从8kHz(窄带narrowband)到48kHz(全频带fullband)
- 帧的大小从2.5ms~60ms
- 支持定比特率(CBR)和可变比特率(VBR)
- 声音的带宽从窄带到全频带
- 支持语音和音乐
- 支持单声道和立体声
- 支持做多255个通道 9.比特率,带宽和帧长动态可调 10.丢包鲁棒性好,且有丢包隐藏(PLC,packet loss concealment) 11.浮点和定点实现方法 12.silk编码可工作最低比特率降低到5kb/s 13.从9kb/s开始可以使用宽带编码
使用LP和MDCT两种变换的原因是,对于低频率的语音LP方法比变换域方法更高效,但是对于语音或者音乐的高频部分变换域方法更为高效。
算法延迟5~62.5ms。在任何时候,要么LP层,MDCT层或者两者在工作。

Opus的超宽带的有效采样率是而不是其它编解码器的,如果要处理的信号,则应该在全频带FB域进行。
LP层是基于SILK编解码器,支持NB,MB,WB音频,帧长从10ms~60ms,需要向前5ms以估计噪声包络。Opus使用的是修改过的SILK,和skype并不兼容。 MDCT层基于CELT(Constrained-Energy Lapped Transform)编解码器。其支持NB,WB,SWB和FB,帧长从2.5ms~20ms,需向前2.5ms数据已满足MDCT加窗重叠方法。音乐应当使用CELT编解码。
编解码的采样率是独立的,并不需要相等,在实现的内部,LP层始终工作在输入信号的两倍采样率上,最大。MDCT的内部处理的信号采样率为。
编码控制参数
比特率
- 8~12 kbps NB 语音
- 16~20 kbps WB 语音
- 28~40 kbps FB 语音
- 48~64 kbps FB 单声道音乐
- 64~128kbps FB立体声音乐
通道选择
OPus可以使用单个数据流传输单声道或者立体声。当用立体声解码器解码单声道帧时,左右声道的解码信号是一样的,当用单声道解码器解码立体声时,左右声道的平均值是单声道的输出。在有些场景下会将立体声编码到单声道编码器中,如当比特率比较低。编码器会根据当前比特率选择最优的通道数。
音频带宽
解码器可以解码编码器编码的任何带宽信号,同时编码器可以将48kHz的信号编码成NB信号,音频带宽越高,需要的比特率越高。
帧长
帧长可以是2.5ms,5ms,10ms,20ms,40ms以及60ms。可以将长达120ms的多帧连续音频编码成待传数据包,对于实时通讯场景,发送更少的数据包能够减少比特率,因为网络传输协议(TCP/UDP/RTP)的开销少了,然而,这会增加延迟和丢包的敏感性,因为一旦丢包,则丢失的编码语音信息将较多。增加帧长可以提高编码的效率,但是对超过20ms的帧长效率提升就不明显了。因此,对于大多数场景,会选择20ms作为单帧语音编码时长。
复杂度
编码的复杂度从0~10依次升高,这影响下面几个部分:
- 基音分析白化滤波器的阶数
- 短时噪声包络滤波阶数
- 残差信号量化估计状态数
- 特定比特流的特性,如可变时频分辨率和基音后置滤波
丢包恢复
音频编码器常用帧间互相关信息来减小比特率,这会导致误差逐帧传递,在丢失一个数据包后,需要多个连续的数据包以便解码器能够精确重构云信号。帧间依赖性的强弱是比特率和误差传播之间的平衡。
前向误差修正(Forward Error Correction)
Inband FEC是抗丢包的另一个机制,对听觉影响比较大的部分,如onset和transient,会被再次以低比特率编码并添加到后续包中。
定比特率和变比特率
当使用变比特率(VBR,variable bitrate)时效率更高,默认就是变比特率工作。
非连续传输(DTX, Discontinuous Transmission)
非连续传输在安静和只有背景噪声的情况时减速比特率,当DTX使能是,每400ms只编码一帧。
内部帧
这是和传输有关的概念,opus将连续的字节流编码成一个独立的块,这里块只包括数据,而不包括传输的TCP,IP等头开销。单个数据包可能包括若干参数集相同的语音帧,这里的参数集指工作模式,音频带宽,帧大小以及通道数等。
TOC字节
Opus包至少包括一个字节,这个字节是TOC(table-of-contents,目录)头,该头表明了该包编码时使用模式和配置信息。该头由配置数字,“config”,立体声标志,“s”以及帧计数组成。

TOC字节
最开始的5个比特制定了32个编码模式中的一个,LP(Silk)和MDCT(CELT)层可以组成如下工作模式: 1.仅SILK模式,对于WB及其更低情况的低比特率场景; 2.混合模式,对于SWB和FB语音在中等比特率 3.仅CELT模式,对于超低延迟和音乐传输,覆盖了NB到FB。

TOC字节配置
s表示的是声道数,0表示单声道,1表示立体声。 c表示的是每包里帧的数量,值为0~3:
- 0:数据包只有1帧;
- 1: 数据包有两帧,每帧压缩后的大小一致;
- 2: 数据包有两帧,每帧压缩后大小不一样
- 3:数据包帧数量是任意的
Opus解码器
Opus包括两个解码器,SILK解码器和CELT解码器。

距离编码
Opus使用基于距离编码的熵编码器,

Voice Quality测试
对于VoIP和智能语音助手等网络传输的场景,使用标准的PESQ(Perceptual Evaluation of Speech Quality)和POLQA MOS(Perceptual Objective Listening Quality Analysis, Mean opinion scores)评估语音质量。
PESQ
PESQ是2001年 P.862标准提出的,P862有三个细分P862.1将PESQ得分转换成MOS度量,P862.2是宽带质量测量,P862.3s是应用指导。该标准对语音质量进行自动化评估,
POLQA
是PESQ的后继者,于2011年提出,其适用于对频带要求更宽的需求(如音乐)。