第二十五章 深度学习-准确的,必要的,清晰的概念
懂得准确的必要的清晰的概念,以及概念之间的联系
DNN(deep neural network)
解决什么问题
早期的时候有感知层,由于感知层的层数比较少,为了解决复杂问题的认知,对于DNN,由于当前层的输入特征是前一层的输出(认识到的特征),当前层是对特征的更进一步处理,可以认识到比上层更复杂的特征,随着网络层数的增加,可以识别越来越复杂的特征。这也可解决输入序列短时相关问题。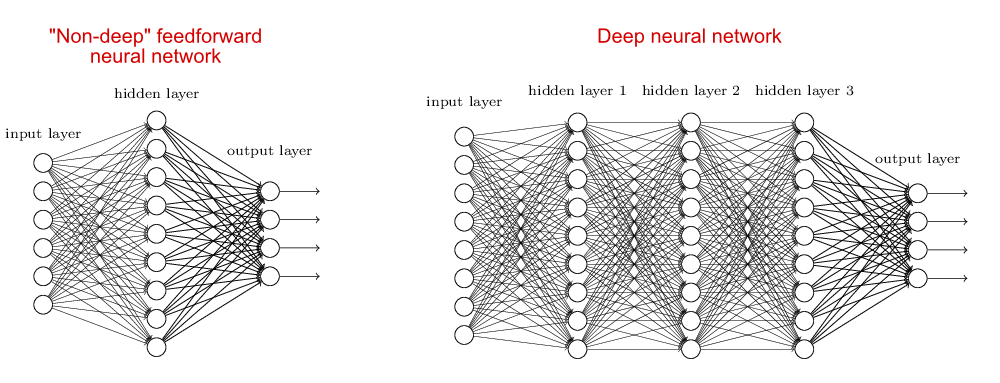
图1. DNN网络结构
使用的方法是
是全连接前向网络+非线性层的组合,如图1。一段tensorflow实现的代码片段是:
```
for i in range(1, num_layers + 1):
with tf.variable_scope('fc'+str(i)):
W = tf.get_variable('W', shape=[layer_dim[i-1], layer_dim[i]],
initializer=tf.contrib.layers.xavier_initializer())
tf.summary.histogram('fc_'+str(i)+'_w', W)
b = tf.get_variable('b', shape=[layer_dim[i]])
tf.summary.histogram('fc_'+str(i)+'_b', b)
flow = tf.matmul(flow, W) + b
flow = tf.nn.relu(flow)
if is_training:
flow = tf.nn.dropout(flow, dropout_prob)
weights = tf.get_variable('final_fc', shape=[layer_dim[-1], label_count],
initializer=tf.contrib.layers.xavier_initializer())
bias = tf.Variable(tf.zeros([label_count]))
logits = tf.matmul(flow, weights) + bias
```
核心就是tf.matmul实现了层与层之间的连接。
CNN
解决什么问题
比如在毕业照集体照中找摸个同学的图片位置,扫描完图片后,你会根据同学的面部特征找到其所在的位置。CNN就是一种在图片中找特征的网络。对于语音也是这样,就是在时频域这个二维图中找声学特征,或者是找字符特征。
相比于DNN,CNN可以获取单帧的时频相关性。
所以CNN网络的一个重要特征,是可以在二维图像中找特征,所以卷积层的结果常被称为feature map,实际上就是原始图像的一个特征映射;还有一种解释,卷积核之间相互正交基,通过这组正交基得到原始图像在各个正交基的所占比重,再根据比重做回归或者分类。
组成
一般包括卷积层,池化层和全连接层
卷积层
对于语音场景,将时域数据变换到频谱,提取时频特征,时频特征可以是MFCC,fbank等,这样的话可以把横轴看成是时间轴,纵轴看成是频域特征轴,这样可以将一段时间内的这幅图组成一个二维特征的图,下图是"VALID" padding 方式的卷积过程示意。
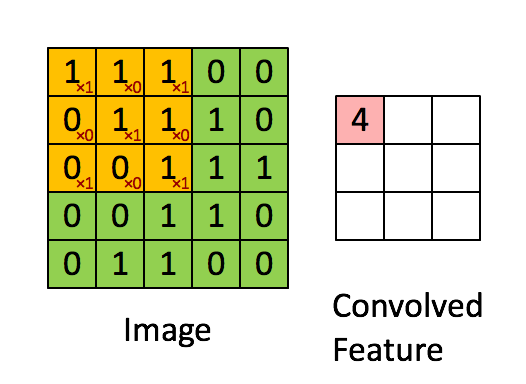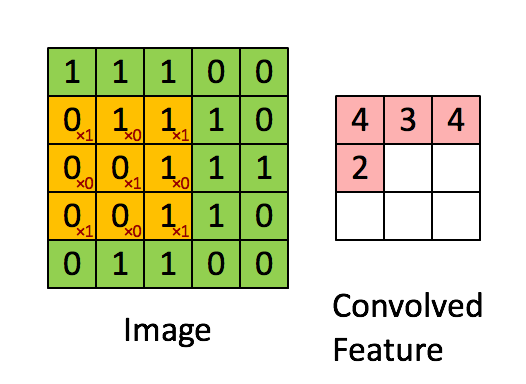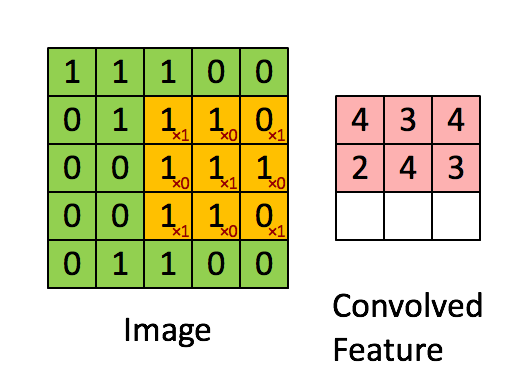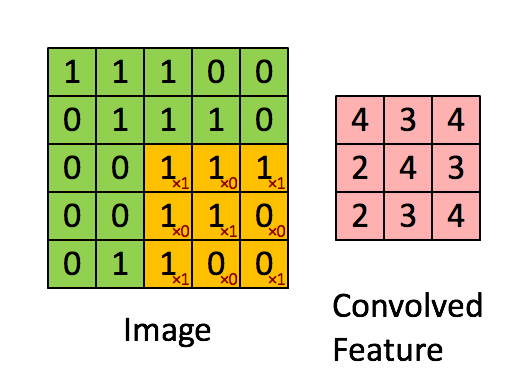
对于彩色图像,一般分为RGB(红绿蓝),下图是“SAME” padding方式的RGB卷积,根据两组权重W0, W1(也被称为卷积核),然后两个feature map;
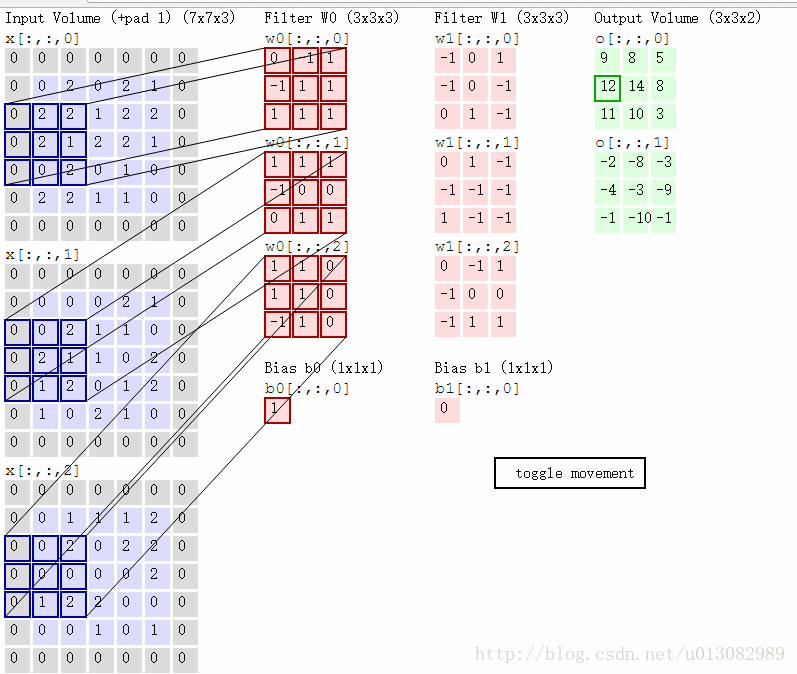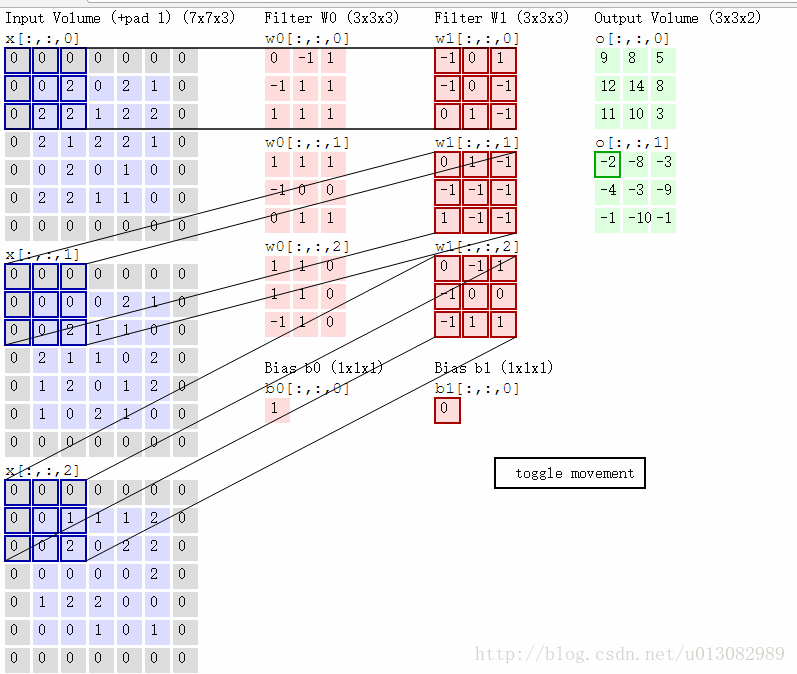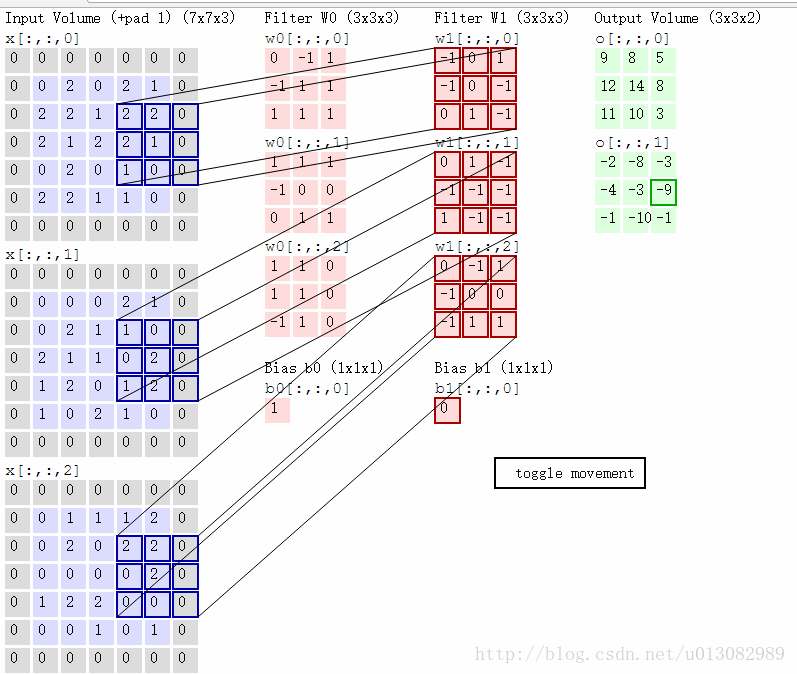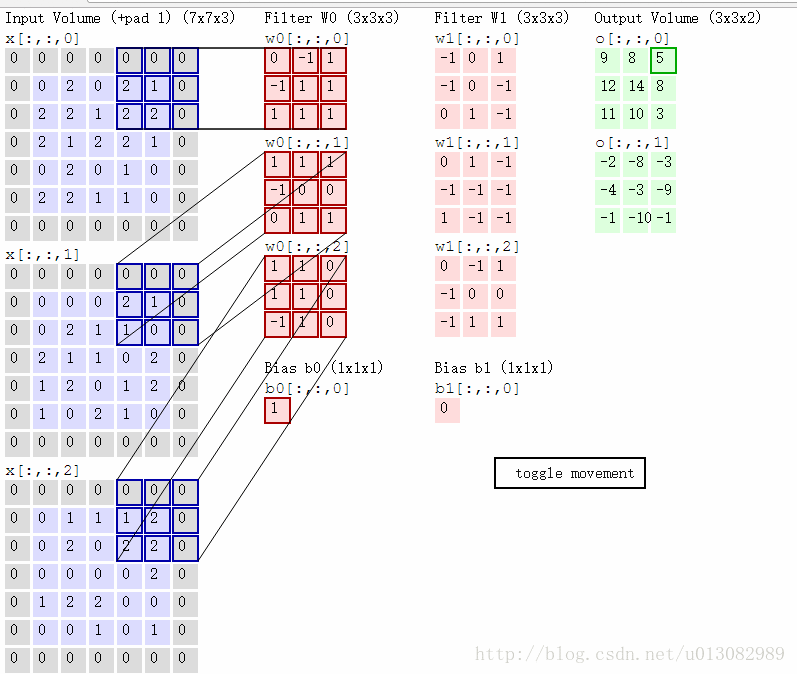
卷积计算过程
tensorflow上的样例是:
```
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)
```
功能:在给定4-D 输入和fliters的情况下,计算二维卷积。
```
input的shape: [batch, in_height, in_width, in_channels]
filter的shape: [filter_height, filter_width, in_channels, out_channels]
```
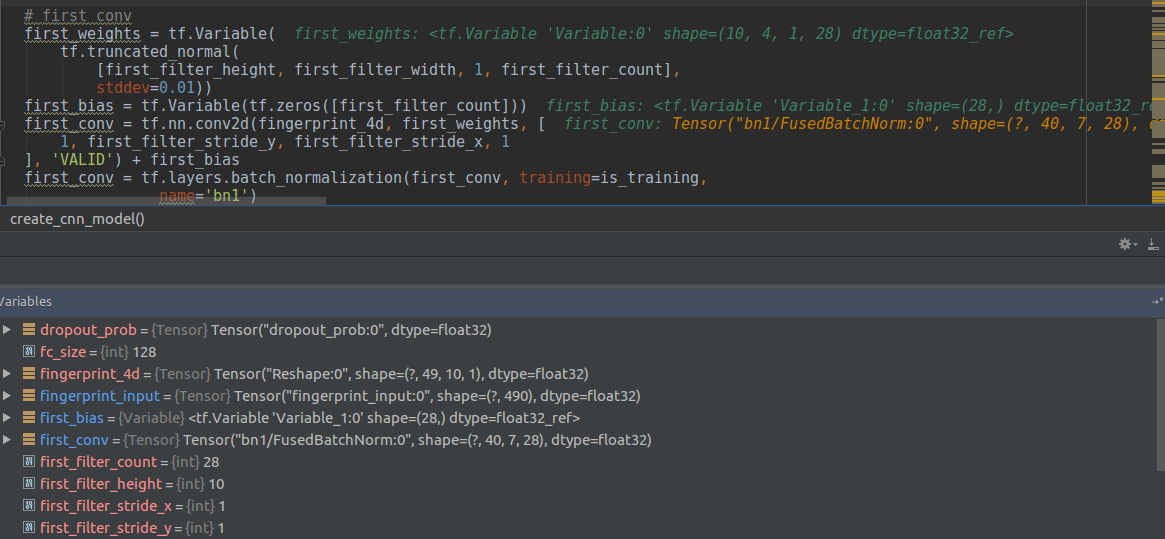
输入fingerprint_4d的维度是(?, 49, 10, 1), 卷积核是(10,4, 1, 28), 其中问号代表的是语音段的标号,这里的(49,10)和上述动图中(77)是一个意思,只不过语音只有一幅图(没有RGB),所以这里只有(49,10,1)最后的数字是1而不是三,(10,4,1)和(33*3)的意义是一样的,而28的意义就是这里的
,只不过这里有一直到
池化层
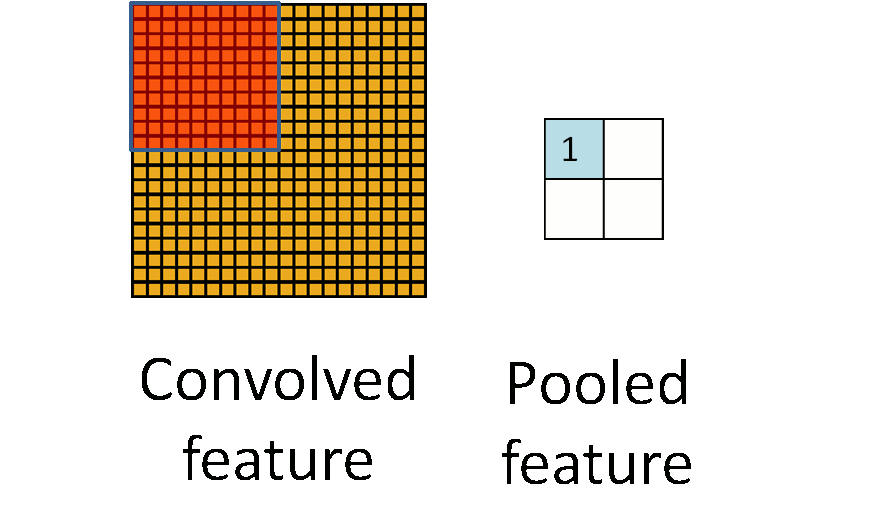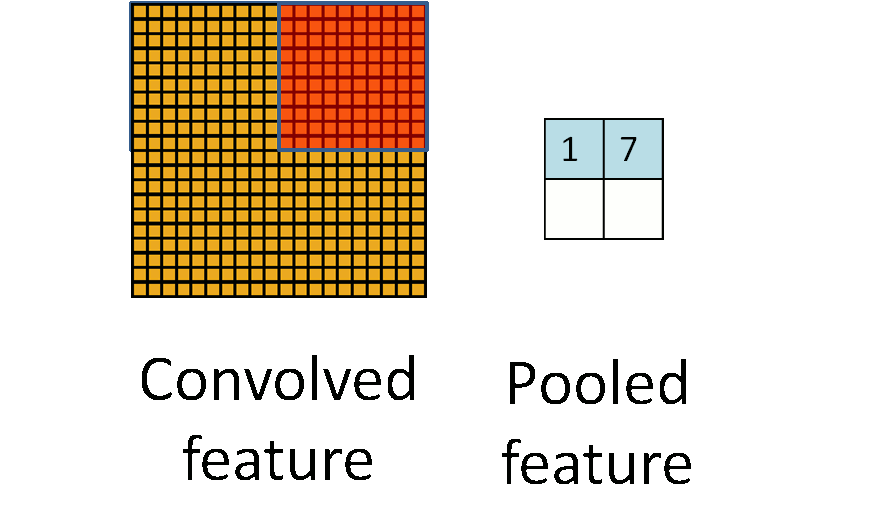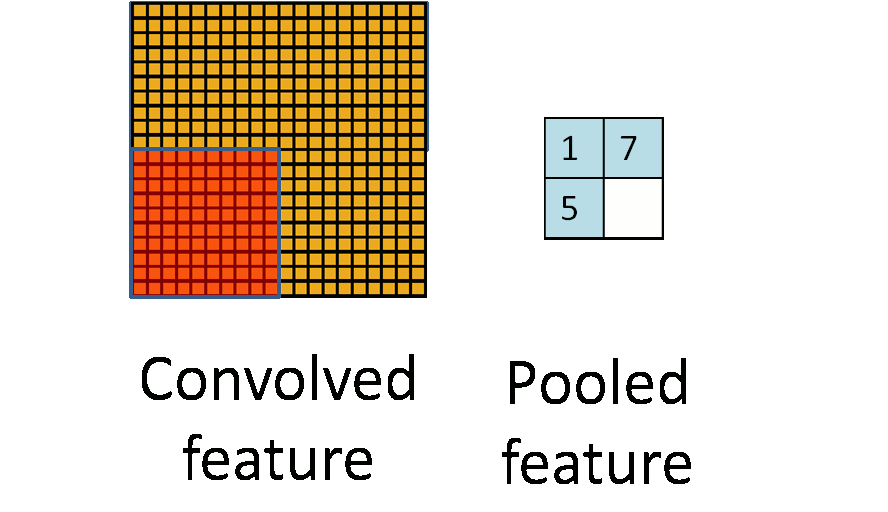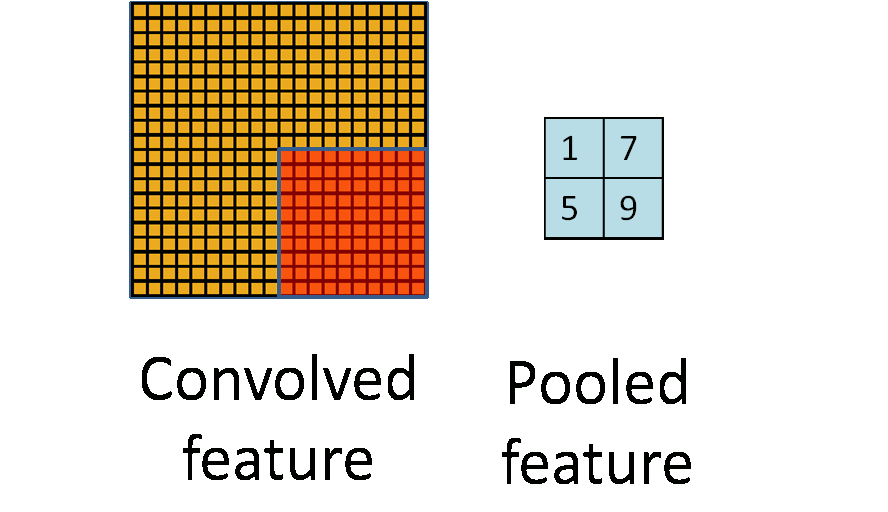
上图可以看到就是把卷积层得到的feature map进行画框选择。
```
tf.nn.max_pool(value, ksize, strides, padding, name=None)
```
第一个参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape
第二个参数ksize:池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1
第三个参数strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1]
第四个参数padding:和卷积类似,可以取'VALID' 或者'SAME'
返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式
LSTM(long-short term memory networks, 1997年提出)
解决什么问题
在CNN中我们解决了根据给定的二维特征图,去提取特征的方法,对于时刻的输入序列,1时刻输入依赖0时刻的影响,但是当t很大时,t时刻的输入还依赖0时刻的影响就很小了,但是这种序列长时依赖关系在现实问题中是存在的,比如,此刻问“这篇文章的副标题是?”,这就需要回退若干个词,才能找到答案,实际中在NLP/NLU中以及ASR中都有paper展现LSTM带来的性能提升。
使用的方法是
标准的RNN结构如下:
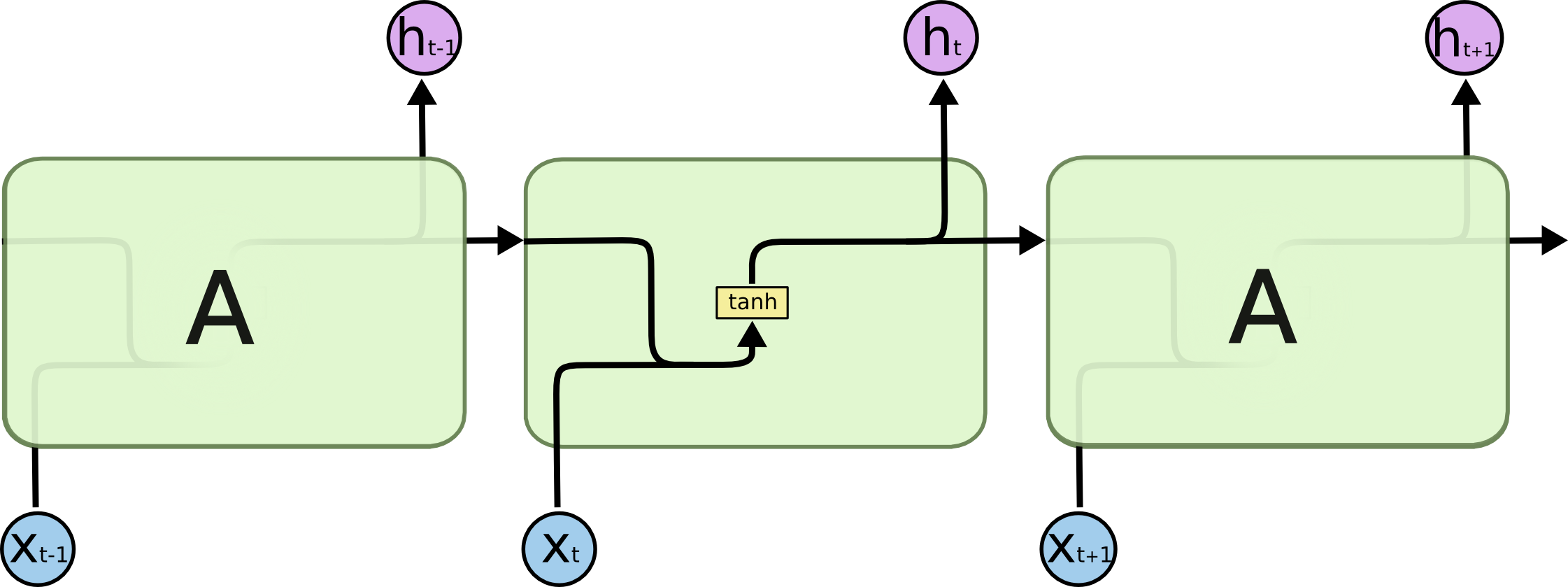
如果让时刻的输入能够影响时刻的输出呢?LSTM的核心思想在RNN的框框里增加一个保存信息的变量。实际实现起来比这复杂些,如下: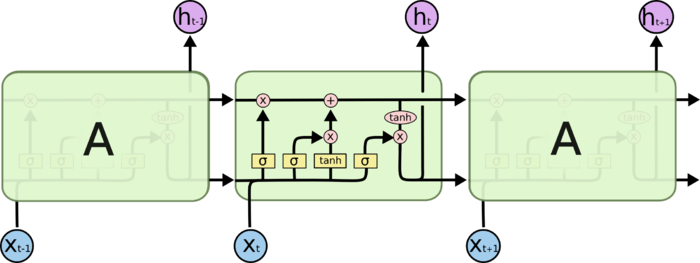
LSTM有三个门,用来保护和控制信息(原始输入和变化过的原始输入)的传递。
1.遗忘门,决定丢弃的信息,该门会读取和,输出一个在0到1之间的数值给每个细胞状态中的数字,1表示完全保留,0表示完全舍弃。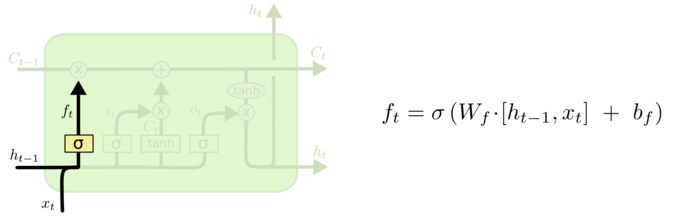
2.输入门,决定跟新的值,包括sigmoid和tanh两层。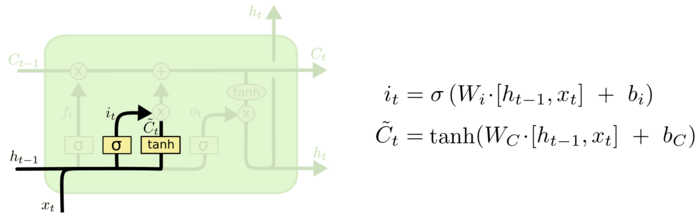
3.更新细胞状态,决定将前级细胞和当前输入细胞输出新的细胞状态.
4.最后还要根据新的输入和细胞状态获得输出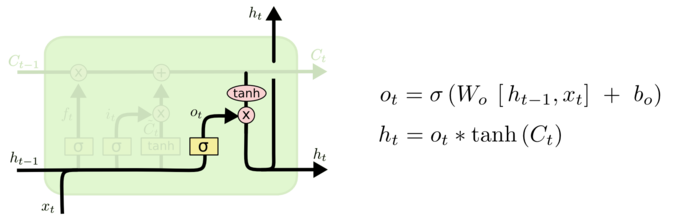
LSTM还有很多变体,由于tensorflow支持peephole connection特性的LSTM变体,就是让门也接受细胞状态的输入。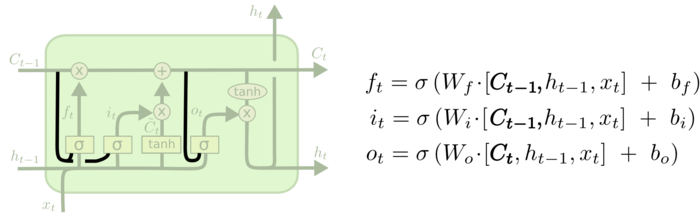
代码实现
 这里根据这张截屏推导Basic LSTM实现下各个参数的size情况。
首先都有对应的权重和biase .上述代码段传递给
这里根据这张截屏推导Basic LSTM实现下各个参数的size情况。
首先都有对应的权重和biase .上述代码段传递给tf.contrib.rnn.BasicLSTMCell的第一个参数LSTM_units值是118,传递给tf.nn.dynamic_rnn的第一个参数就是上述生成的LSTM cell, 而input是(?, 49, 10),其中?是batch, 49是时间维度,对应的时间点, 10是每个时间表示特征的维度,输出有两个变量,第一个是输出维度是(?,49,118),第二个是last,其维度是(?,118).
所有h的维度是118,所有x的维度是10,这样的维度就是128了。所有w的维度是128118,(128就是对应于输入特征向量的长度),相乘后得到1118(实际中的1会变成batch size,也就是?×118)。而且在实际计算时,会把所有的w组合在一起做和乘的动作。
另外:最好的方式是针对特定的例子,使用tensorboard 来看,另外,停止过度学习,如果没弄懂,不要继续向下阅读(除非你目的就是这样),弄懂这个概念再向下学习。
GRU(Gated Recurrent Unit 2014年提出)
解决什么问题
GRU是LSTM一种变体,也用来解决长时依赖问题,要比LSTM简单,改起来方便。这就让调试变得简单和训练的速度也变快了。
使用的方法是
将LSTM的遗忘门和输入门合成一个单一的更新门。同样还混合了细胞状态和隐藏状态和其它一些改动。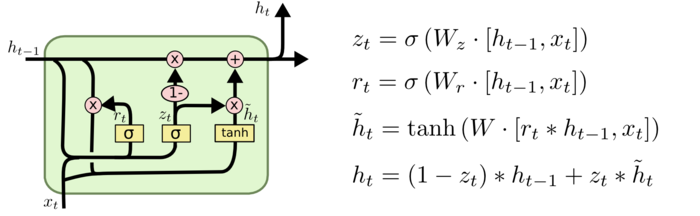 和LSTM类似.
和LSTM类似.
DS-CNN
相比云端,嵌入式设备端在运算和存储资源差异上非常大,为了获得CNN处理细节特征的好处以及RNN处理时间序列的能力,通常在嵌入式设备上也会将这两种网络组合使用,但对于主频100MHz,memory只有几百KB嵌入式系统的资源情况,DS-CNN主要是在获得CNN的好处的同时减小对资源的消耗,常用于嵌入式端的图像和语音识别。
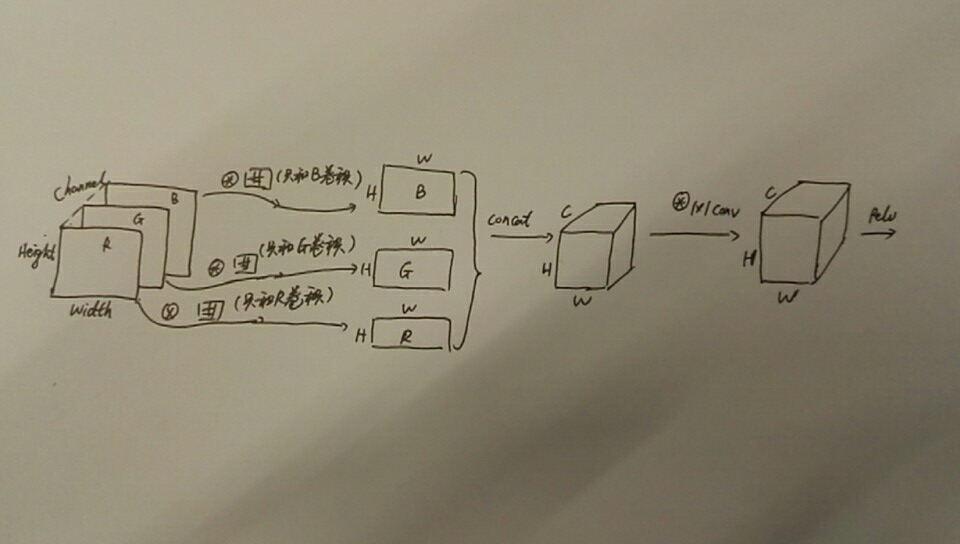 depth-wise的卷积过程如上图。
depth-wise的卷积过程如上图。
CTC
ResNet
解决什么问题
使用的方法是
Batch Normalization
【参考文章Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift】
解决什么问题
在训练深度神经网络时,每层的输入由所有前面各层的参数和原始输入共同决定,当网络变得更深更复杂时,网络参数的微小变化会被逐级放大,为了让饱和非线性(多数是这种模型)深度网络正确收敛;就要求使用较小的学习率和精心选择各层参数的初始值,以避免训练过程中输入参数分布发生变化带来的不确定性,这个现象被称为内部协变量转移[Covariate shift],而标题Batch Normalization就是用来解决这个问题。
使用的方法是
通过归一化各输入层的均值和方差以去除covariate shift影响,这被称为batch normalization,该方法还有一个好处是原始输入对经过归一化的输入影响变小。
对每一层输入的整个进行白化的代价是昂贵的,batch方法做了两个必要的简化。
第一个简化是单独标准化每个标量特征,是其具有零均值和单位方差。对于具有d维度输入,对每一维的标准化是:
其中期望和方差在整个训练数据集上计算。即使特征没有去相关也加速了训练过程。
这种简化会改变每层可以表示什么,例如,标准化sigmoid函数输入会将其限制到非线性的线性状态,这可以引入成对参数和来确保归一化前后是恒等变换,他会将归一化和移动标准化值:
这些参数和原始的模型参数一起学习,并恢复网络的表示能力。
第二个优化:由于在随机梯度方法中使用小批量(mini-batch),为每个激活函数估计每一个batch的均值和方差(而不再是再所有训练数据集计算,对于海量训练集的数据情况,全局计算梯度和方差几乎是不可行的)。
对于大小为的小批量数据.
所以计算步骤看起来如下:

tensorflow调用格式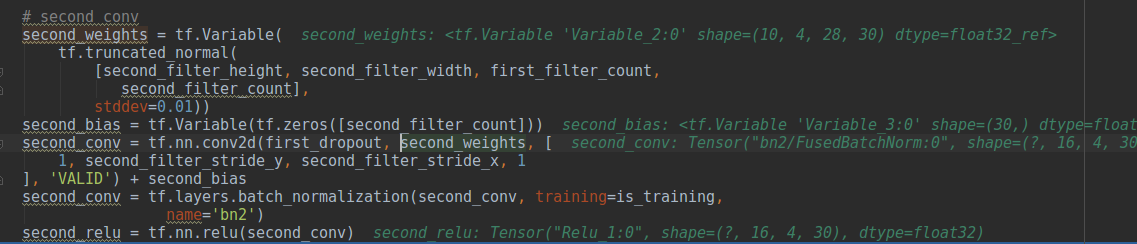
达到的目的是
1.对原始神经网络参数选择并不敏感; 2.可以选择较大的learning rate以加快收敛速度; 3.batch normalization正规化了模型减小了对dropout的需求; 4.深度神经网络更容易使用饱和非线性方法
dropout
tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None, name=None)
根据给出的keep_prob参数,将输入tensor x按比例输出。默认情况下, 每个元素保存或丢弃都是独立的。以keep_prob的概率值决定是否被抑制,若抑制则神经元为0,若不被抑制,则神经元输出值为,.
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
d = tf.constant([[1.,2.,3.,4.],[5.,6.,7.,8.],[9.,10.,11.,12.],[13.,14.,15.,16.]])
print(sess.run(tf.shape(d)))
#由于[4,4] == [4,4] 行和列都为独立
dropout_a44 = tf.nn.dropout(d, 0.5, noise_shape = [4,4])
result_dropout_a44 = sess.run(dropout_a44)
print(result_dropout_a44)
#noise_shpae[0]=4 == tf.shape(d)[0]=4
#noise_shpae[1]=4 != tf.shape(d)[1]=1
#所以[0]即行独立,[1]即列相关,每个行同为0或同不为0
dropout_a41 = tf.nn.dropout(d, 0.5, noise_shape = [4,1])
result_dropout_a41 = sess.run(dropout_a41)
print(result_dropout_a41)
#noise_shpae[0]=1 != tf.shape(d)[0]=4
#noise_shpae[1]=4 == tf.shape(d)[1]=4
#所以[1]即列独立,[0]即行相关,每个列同为0或同不为0
dropout_a24 = tf.nn.dropout(d, 0.5, noise_shape = [1,4])
result_dropout_a24 = sess.run(dropout_a24)
print(result_dropout_a24)
#不相等的noise_shape只能为1
输出:
[4 4]
[[ 0. 4. 0. 8.] [ 0. 0. 14. 0.] [ 0. 0. 22. 0.] [ 0. 0. 30. 0.]] [[ 2. 4. 6. 8.] [ 0. 0. 0. 0.] [ 18. 20. 22. 24.] [ 26. 28. 30. 32.]] [[ 0. 0. 6. 0.] [ 0. 0. 14. 0.] [ 0. 0. 22. 0.] [ 0. 0. 30. 0.]] ```
梯度消失问题
对于具有sigmoid激活函数,是输入层,权重和偏移是待学习参数;。当增加时,梯度变小。这就意味着当x较大时,梯度接近于零(梯度消失),这一梯度影响会被逐级放大,而参数的更新是依赖梯度的,接近于0的学习率,意味着收敛的速度非常慢。慢到一定程度是不可接受的。
RELU
对于饱和问题和梯度消失问题,常使用RELU方式进行规避,,这样就不会导致sigmoid函数的输出接近于0了。
用法: