第二十四章 基于深度学习(deep learning)的语音增强
深度学习方法正成为新的解决语音增强的方法,由于以物理模型为基础的方法都有诸多的前提假设,比如在去混响时,会假设语音符合高斯或者拉普拉斯分布,实际上这些假设和真实场景上还有差距,深度学习方法却可以在接近真实场景上更进一步.
在第六章的NS算法中提到,在判决是否是噪声时,使用到了频谱平坦度,谱减法,语音噪声高斯统计模型以及子带和频点处理相关技术.在深度学习方法中,统计模型不再是一开始认为将其设置成高斯模型,而是通过训练数据训练出来,同样频带的数量也是可以通过深度学习方法习得.
随输入特征选取的不同,网络的结构会有差异,有使用类似ASR的特征做为DL输入特征,也有使用幅度和相位做为输入特征的处理方法.
DL可以用于从第一章至此的任意一个章节,并且谷歌和亚马逊在他们的实现中,服务器测还采用了DL方法进行的语音增强.
开发环境pycharm
sudo add-apt-repository ppa:ubuntu-desktop/ubuntu-make
sudo apt-get update
sudo apt-get install ubuntu-make
umake ide pycharm
umake -r ide pycharm
本书是为ASR服务的,所以不得不提到前端语音增强和ASR分离带来影响问题,从前文可以看出NS/AEC/BF/DR/DOA/VAD等这些算法除了基于有限的统计模型的组合外,还有这些模型推导公式所使用的判决准则,如最小均方误差准则,最大声学似然比,不仅是这些判决准则不是以ASR为目标的,就连处理过程(如:NS的谱减法等,实际上就是没有关注SDR, signal distortion ratio)也不是以ASR为目标的,所以如果单单是使用深度学习的方法进行NS,或者单单做去混响操作,方法本身没有问题,但是判决准则同样不是以ASR的识别率为目标的,这样的化从各个模块来看是可以达到模块最优,但是以ASR这一全局的结果来看,这些局部最优组合起来未必能够达到全局最优,所以更好的方式是以ASR识别率做为检验的标准,声学模型用多通道的数据(当前训练数据相对少些)进行训练,这样语音增强算法和声学模型算法可以更好的融合(它们的目标是一致的:ASR识别率,模型之间在训练中可以进行反馈和调整,这样可以达到全局最优).所以章就以带识别情况为例说明深度学习在语音增强上面的一些应用思路,如果对语音识别不太熟悉,不妨先看第17章.
CNN卷积运算过程例1 CNN卷积运算过程例2 RNN/LSTM/GRU简介
beamformering DNN
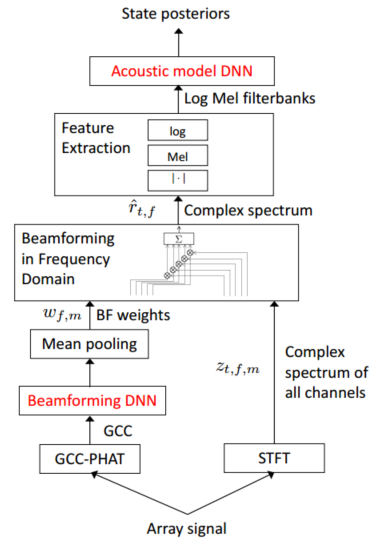
注:摘自[Deep BEAMFORMING NETWORKS FOR MULTI-CHANNEL SPEECH RECOGNITION]
从图15.1可以看出,该特征提取模块和大多数基于DNN方法的ASR识别方法没有大的差异,bf的模块主要是训练波束形成的权重,对于输入的阵列信号,分成两个部分,一个部分是做STFT,每一个通道都获得复数的频谱,t是时间戳,f是频率点,m是麦克风的通道号;另外一路是做GCC-PHAT,这常用于DOA算法,且类似delay-sum的方法也是先根据方向在做波束形成的,也就是波束形成的权重是和声源的方向有关的,这边的beamforming DNN模块的输入是GCC-PHAT值,这样获得的信息要比具体的声源目标位置要多,所以理论上权重也应该更优.mean pooling是对采集到的每句话做均值平均,这样会得到权重,根据这个权重和STFT的结果相称后得到频域权重.
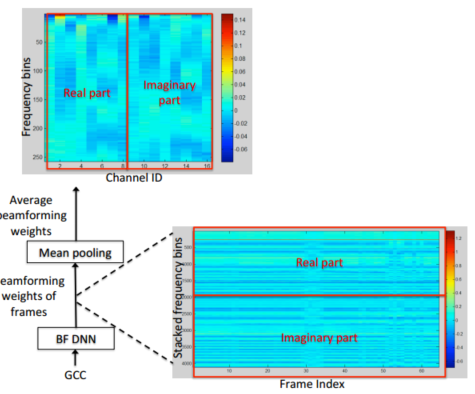
还有一篇文章也是非常的有启发.文章指出WER有5%的提升.该文章基于的思想是DNN可以将特征提取和分类问题合二为一,这样的化可以使用原始数据输入这个网络,而非向上一篇文章需要现在特征提取,这样可以联合高效进行特征提取和分类.
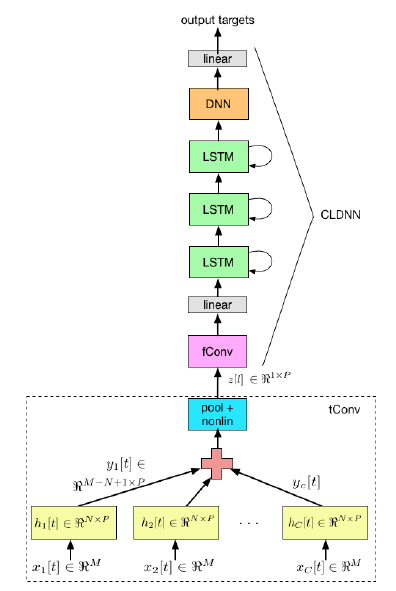 注:摘自[Multichannel Signal Processing with Deep Neural Networks for Automatic Speech Recognition]
注:摘自[Multichannel Signal Processing with Deep Neural Networks for Automatic Speech Recognition]
该文章采用卷积LSTM深度网络声学模型,第一层通过短时多通道卷积滤波器将多通道数据映射成单通道数据,黄色的部分是空域滤波器,所用神经网络使用异步随机梯度下降法(asynchronous stochastic gradient descent ASGD)减小的交叉熵(cross-entropy CE)来进行训练.
该多通道CLDNN波束形成思想源于filter-sum方法,对每个麦克风使用FIR滤波器滤波后再相加,这一过程可以用下式表示:
其中n是滤波器阶数,c是麦克风通道数,是滤波器系数,是原始麦克风数据,是输出信号.
式12.1中值常通过DOA获得的获得,通过MVDR 等准则获得,而在图3中获得的方式有所不同,图中将延迟和滤波器系数根据声学模型最优准则进行联合训练.
该模型使用一组p通道的滤波器获取延迟,滤波器的输出可以写成下式:
这里的是延迟和FIR滤波器的综合.是卷积运算. 公式2可以使用多通道卷积运算实现,图12.2中的,每个通道数据(数据长度是M)都和P个滤波器(滤波器阶数是N)组进行卷积
卷积结果输出是
对c个通道按时域进行max pool后(丢失短时相位信息)得到输出.然后进行非线性对数压缩获得输出。
本章小节
至此本章把语音增强的大致方法理了一个脉络,对于BF以及VAD等也只是阐述了基本原理和一个实例,并没有遍尝绝大部分方法,也就没法给出方法之间的性能差异,再比如对于盲源分离问题,并没有给出实例,另外对于ASR云端服务,也没有阐述数据压缩的方法和压缩实例。 本章简介了一下深度学习在语音增强上的应用,实际上从上文的分析来看,对于ASR识别场景,语音增强更适合于混合如声学模型的训练网络,根据最终的ASR识别率来反馈调节各个具体的语音增强模块和声学模型模块。 所以本章大致介绍了语音增强在深度学习的网络结构,并着重分析了一篇声学模型和波束形成混合的一篇文章,这篇文章对于使用深度学习方法解决识别问题很有裨益。
这里匆匆结束语音增强相关的内容,在下一章将进入语音识别方面的内容,并且深度学习的方法也都放在ASR的内容进行讨论.