第五章 自动回声消除(AEC)原理
回声消除是为了消除机器自身发出的声音,不影响外界传递过去的声音,如在通话场景中,来自远端的经过扬声器放出来的声音被消掉,否则经过麦克风采集和近端说话人信号混在一起被传递到远端,则会出现远端的人听到自己说的话,这种体验不好。在远场音箱交互场景中,这自动回声消除的难度比通话场景要复杂一下,主要的原因是近端说话的语音是淹没在大功率喇叭且存在低音单元之中的。
回声消除原理
回声消除的基本原理是用一个自适应滤波器对未知的回声信道进行参数辨识,根据扬声器信号与其产生回声信号相关性为基础,建立远端信号模型,模拟回声路径,通过自适应算法调整,使其冲击响应和真实回声路径相逼近。然后将麦克风接收到的信号减去估计值,即可实现回声消除功能。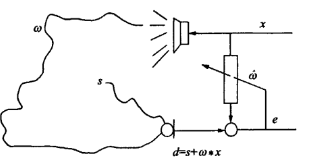
式中,是回声通道的时域冲击响应函数;是远端语音;echo是所得回声;s是近端说话人语音,d为麦克风采集到的信号;为对回声信号的估计值;e为误差。在电话、视频会议中,x指通话另一端的语音信号,而在机器语音识别场景,则指机器自身扬声器发出的声音。
为了消除延迟较大的回声,FIR滤波器的阶数要尽量的大。时域计算诸多不便,使用频域分块自适应滤波算法,提高实时性。涉及到的信号处理术语:
- FFT/IFFT
- 循环卷积和线性卷积的关系;重叠保留法
- 功率谱密度
- 互相关
- LMS/NLMS自适应算法
- 频域分块
- 宽带信号处理
维纳滤波
均方误差(MSE,Mean Square Error),对于离散时间系统,可定义期待响应为一个希望自适应系统的输出与之相接近的信号,k为采样时刻。
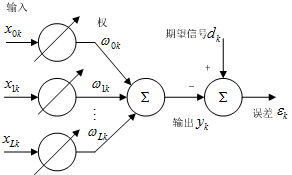
根据图2, 可以求得误差信号:
自适应线性组合器输出:
其中:
分别为自适应系统在k时刻的输入信号向量和权向量,系统的均方误差为:
令:
定义期待响应和输入信号之间的互相关向量为:
将式9简化成下式:
理想情况下等于零,是估计值等于观测值,误差越小, 对式10求偏导数,得:
最佳权向量处的梯度等于0,于是:
最小均放误差输出情况下的最佳权向量满足维纳-霍夫方程:
值得指出的是MSE准则应用的地方还是很多,在后面阵列波束形成中的一个实例就会用到这一准则。
LMS算法
式中,为输入样本向量,使用单次采样数据来代替均方误差,这样梯度估计可表示为如下形式:
基于最速下降法的权向量迭代如下:
其中是步长因子,, 是的最大特征值。收敛于由比值决定,该比值决定,他的比值叫做谱动态范围。大的d值意味着较长的时间才能收敛到最佳权值。
该算法用在语音增强的加性噪声消除功能上时,其工程实践并不完全按照式14意义来实现。
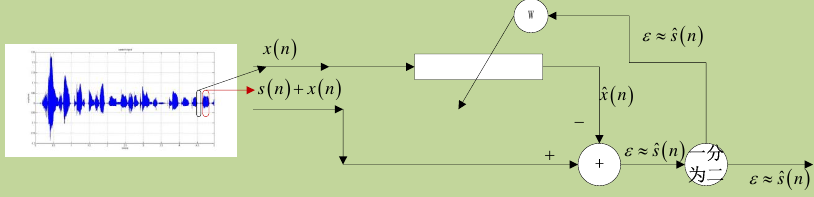
自适应LMS算法在主动降噪中的应用

算法的原理,假设是图一中麦克风采集到的消声后的信号,是真实的环境噪声信号,被称为参考信号,这可以通过麦克(非耳塞上的麦克)来获取, 而是扬声器发出的信号,用这一加权值来预测的值,如果预测的准,那么就等于0,即麦克风的震膜没有震动,人也就听不到噪声了。这个算法称为LMS算法。
在语音增强中,其目的是获得纯净的语音信号即上图中的最后输出信号,输入信号有两种,一种是带噪的语音信号,另一种是只有噪声的输入,在没有人说话的情况下的输入信号,就仅仅是噪声输入。 这里要使得噪声估计非常接近,对于,这时如果最小,则可以估计出的最接近。该过程可以概述如下:
- 首先获取到噪声输入,并存储下来,以64或者128点为总长度不断刷新存储噪声输入。
- 采集带噪声的语音信号。
- 用采集带噪语音信号减去估计到的噪声信号s(n)+x(n)-\hat x(n)。
- 用3的输出作为误差,调节噪声权向量W。
MATLAB实现具体包括如下三个部分:
% Loop over input vector
for ii = 1:length(signal_with_noise)
% Update buffer
%输入噪声估计
noise_buf = obj.update_buf(noise_buf, noise(ii));
% Filter this sample with current coefficient values
%通过权向量估计
filter_output = obj.data_filter(coefs, noise_buf);
% Compute error,相减得到
err = signal_with_noise(ii) - filter_output;
% Update coefficients
coefs = obj.update_coefs(coefs, noise_buf, obj.filter_params.step_size,
%用调节权向量
obj.filter_params.leakage, err);
% Build output vector
%存储输入信号的估计值
dout(ii) = err;
NLMS算法
当输入信号幅值较大时,梯度噪声方法会遇到问题,使得能量低的信号算法收敛速度比较慢,将输入信号按照自身的平均能量进行归一化处理,既可以得到归一化的LMS算法(NLMS),鲁棒性比较好。设输入带噪信号可以表示为:,其迭代算法NLMS公式如下:
其中,,其中,N是噪声消除器和回波抵消器的长度。(常取512,1024); 是步长因子。当较小时, 的值可能较大,这是迭代算法变成如下形式:
其计算过程如下:
参数:M是滤波器抽头系数(阶数),是自适应常数,, 其中,是权向量均方偏差,是最优维纳解,是第n次迭代中得到的估计值。是带噪输入语音信号的功率,是误差信号功率。
计算过程
1.初始化过程
如果知道抽头权向量的先验知识,则用其来初始化,否则令。
2.数据按帧处理
A)给定的第n时刻抽头输入向量,是第n时刻的期望响应.
B)要计算的:是第n+1步抽头权向量估计
3.计算
对计算:
此外还有NLMS变种的各种方法,如SE-LMS(signed-error)LMS, SD-LMS(signal-dependent LMS),LLMS(Leaky LMS), LNLMS(Leaky NLMS).
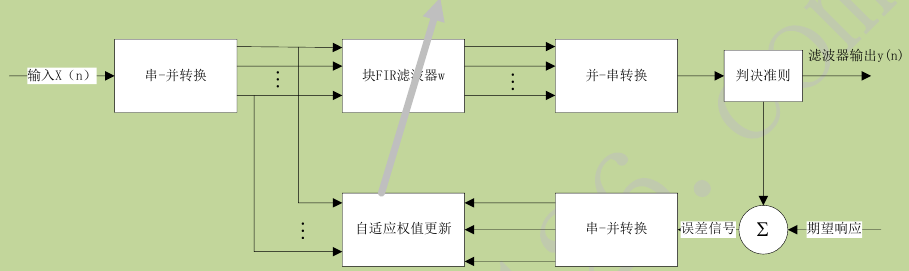
块自适应滤波
对参考信号x分段并做FFT变换,分别对各段数据做频域滤波,累加后做FFT反变换,并只取后L(L是原始信号的分段后的长度)点为有效的线性卷积结果,得到的是估计信号,将估计信号从回声信号中去除,得残差信号。计算子带步长,调整各段滤波器系数。这一过程表示如下图。
设n时刻输入序列如下:
对应于长度为M的FIR滤波器在n时刻的抽头权向量为:
根据FIR滤波器原理:
用向量表示如下:
下面对进行分块,设k表示块下标,它与原始样值时间n的关系为:
其中L是块的长度。 第k块的数据为,其矩阵表示形式如下:
将滤波器对输入块的响应表示如下:
设表示期望信号,误差信号表示如下:
考虑滤波器长度M=3,块长度L=3,其三个相邻的数据块是k-1,k, k+1,则第k-1块滤波结果如下:
则第k块滤波结果如下:
则第k+1块滤波结果如下:
上面的数据矩阵是托伯利兹矩阵,主对角线元素都相同。
权向量调整公式如下
(权向量的调整)=(步长参数)*(抽头输入向量)*(误差信号)
因为在块LMS算法中误差信号随抽样速率而变,对于每一个数据块,我们有不同的用于自适应过程的误差信号值。因此,每一个块的抽头权向量更新公式如下:
其梯度向量的估计如下:
的无偏估计如下:
块LMS算法的收敛性
由于时间平均的缘故,它具有估计精度随快长度增加而大幅提高的特性。然而,长度的增加会导致其收敛速度进一步减慢。后文的快速LMS算法加速了这一过程。
平均时长数
其中,是输入自相关矩阵
上式中为了使零阶公式成立,必须小鱼,其中是相关矩阵的最大特征值.
失调
其中是相关矩阵的迹.
块长的选择
滤波器长度M和块长度L的关系有三种可能:
1.,从计算的复杂性上看,最佳。
2.,有降低延迟的好处。
3.,将产生自适应过程冗余运算。
FLMS(频域LMS)
不论是webRTC还是speex开源的AEC算法都是基于频域来做的。之所以放在频域而非时域实现的主要原因实时性,在16kHz采样率的情况下,屋子里的回声持续时间长达0.1~0.5秒(多次反射),这就要求自适应滤波器的抽头数达到8000之多,工程上在考虑到计算量和延迟因素时基本都选择在频域实现。
FLMS(Fast LMS)的基本思想是将时域块LMS放到频域来计算。利用FFT算法在频域上完成滤波器系数的自适应。快速卷积算法用重叠相加法和重叠存储法。重叠相加法是将长序列分成大小相等的短片段,分别对各个端片段做FFT变换,再将变换重叠的部分相加构成最终FFT结果,重叠存储法在分段时,各个短的段之间存在重叠,对各个段进行FFT变换,最后将FFT变换得结果直接相加即得最终变换结果。当块的大小和权值个数相等时,运算效率达到最高。
根据重叠存储方法,将滤波器M个抽头权值用等个数的零来填补,并采用N点FFT进行计算,其中,因此,N*1的向量:
表示FFT补零后的系数,抽头权向量为 。值得注意的是频域权向量的长度是时域权向量长度的两倍。相应的令:
表示对输入数据的两个相继字块进行傅里叶变换得到一个对角阵.
将重叠存储法应用于3.26得:
每处理一帧,式37只有最后的M个元素被保留,因为前面的N个元素是循环卷积的结果.
设第块的期望响应和误差信号分别如下:
根据式3.37,可将变换到频域,即
则在更新权值的相关矩阵如下:
,
的最前面M个元素,则抽头更新过程在频域中的表现如下:
MDF自适应权值调整
时域解 对于N阶NLMS算法,其误差调节向量如下式:
权值更新如下:
其中是参考信号,是时刻和步长的权值更新。 假设滤波后的误差为
则误差的迭代关系如下:
在每一次调节中,滤波器的误差估计为,展开后得如下形式:
如果和是不相关的白噪声信号,则如下式:
可以通过求解
:
求解后得到最优步长:
期望等于剩余回声的方差,如果剩余回声的方差值等于0,则步长因子等于1,,则有输出信号的方差是:
这样可以求得这种情况下的最优步长因子为:
则最优步长因子如下:
当时,式45停止迭代。将50带入51得到在滤波器系数不更新情况的剩余回声:
- 频域解
和时域相比,频域可以使步长因子按频域划分,和分别是频域中的记号,其和时域中的和是对等的关系,k是频域索引,l是帧索引,和3.49类似,可得频域步长因子:
假设滤波器有一个和频谱无关的泄露(滤波器的误差)系数,这将得到:
实际上是滤波器回声返回损失增强ERLE。
为了让步长因子调节的更快,使用瞬时估计,
和
这将使得3.50步长因子变为:
是小于等于1的数,以确保滤波器稳定。
工程中的思考
关于步长因子
对于视频通话这类场景,两个通信终端的时钟偏斜和漂移是不定的,而音箱场景这个是可以在硬件上加以解决的,但是音箱场景的非线性失真却比通信场景严重的,功率放大模块非线性器件带来的谐波失真,在室内四个方向都发声,是得卷积失真,多次反射回声,声音突变等会加剧问题处理的复杂性;
当前绝大部分的AEC算法基本都基于频域分块处理方法,基于LMS/NLMS、RLS(recursive least square), APA(Affine Projection Algorithm)自适应处理方法。该自适应方的基本公式是:
这个公式中误差信号e是维纳滤波(相减)后可以计算得到的,而步长因子却无法直接求得,在有些场景中,根据线性代数推导,在稳定性和收敛速度的双重约束下可以得到步长因子要满足步长因子小于输入信号协方差矩阵的迹的导数:
针对LMS的一个改进是NLMS算法,这个方法根据输入输入信号的功率对步长进行归一化:
其中是归一化步长因子,.为了防止分母为零,加小数a,得如下计算公式:
这样收敛速度和输入信号的功率绝对值无关。但是这两种算法在输入信号相关性在很高时收敛速度会比较慢。更进一步的可以采用自适应NLMS算法: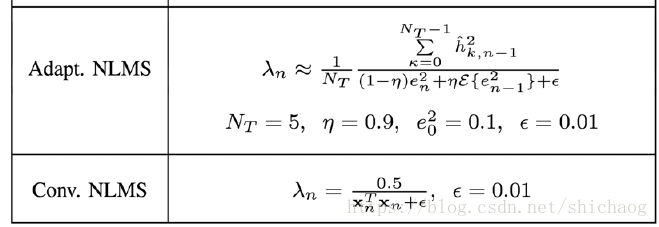
关于误差信号
LMS算法消除了线性部分,得到的是残余线性部分和非线性部分之和,非线性部分源于外界的噪声,参考源的卷积响应以及喇叭或者传输路径的影响,常用的方法可以
RERL:ERL+ERLE
RERL:residual_echo_return_loss
ERL:echo_return_loss
ERLE:echo_return_loss_enhancement
psd:power spectral density 功率谱密度
x: far end
d: near end
e: error
s: psd
nlp:non-linear processing
ERL vs ERLE
ERL :echo return loss = (mic in power) / (ref power)
ERLE :echo return loss enhancement = (power of residual echo signal) / (mic in power)
ERL和麦克风采集到的带回声信号和参考信号的比值,单位常用dB表示,比值越高,反映的是回声信号越小,大多数的VoIP设备的ERL值在15~20dB之间。
REC(residual echo control)
使用滤波器来近似非线性响应函数,这样也会得到非线性估计,实际上最早开始部分提到的误差信号e是减去了线性和非线性部分得到的误差信号,滤波器系数可以通过最小能量均分来做为准则进行平滑。大部分AEC算法的较大差异在非线性部分/后处理部分,通常希望滤波器阶数较高,能够处理较长的时间长度(即信号经过多次反射到达的场景)。比较有名的处理的滤波器是volterra 滤波器,使用一阶,二阶和三阶滤波器来去除非线性部分,但随着阶数的增加,计算量也呈现指数方式增加,其一阶的表示式如下:
二阶的表示如下:
则误差信号可以表示为:
则滤波器的系数更新方程如下:
这里涉及三个步长更新速率,, , ,当时,这一过程是收敛的。
非线性问题
由于扬声器的失真以及传播的非理想性,维纳滤波并不能完美的解决AEC的问题,一般在经过维纳滤波之后会再经过RES和/或NLP,这个模块的核心思想是提取信号的有用信息(如,误差信号和远端信号的互相关性以及误差信号和近端信号的相关性,以及远端和近端信号的相关性)计算相应频点的缩放因子,以实现在输出的误差信号中进一步压制误差信号。
结束语
本章主要阐述了AEC要解决的问题,以及常用的时域和频域解决方法,值得一提的是,产品结构布局影响还是很大的,市场上绝大多数智能音响产品的喇叭和麦克风一般在物理尺寸的两端(圆柱形的外形,一般麦克在顶部,喇叭在中下部,且喇叭开口朝下,通过反射锥以弥补听感上损失),可以收音和发音方向相反且隔开的。
有了以上理论,可以从开源的实例(WebRTC MATLAB and c code github Address),下一章以webRTC为实例,剖析MATLAB和C代码,在我的github上有相关开源代码的使用实例。需要注意的是我代码里给定的默认设置值,不一定针对你的场景是最优的,但是效果一定是可以听出来的。