第二十九章 kaldi入门
代码下载和安装
$git clone https://github.com/kaldi-asr/kaldi
根据INSTALL文件,先完成tools文件夹下的编译和安装,然后在编译src目录下源码。
$cd kaldi/tools
$extras/check_dependencies.sh
$make -j4
然后切换到src目录
$cd ../src
$./configure
$make depend
$make -j4
kaldi依赖的工具
- OpenFst 加权有限自动状态转换器(Weighted Finite State Transducer)
- ATLAS/CLAPACK标准的线性代数库
这两个在解码和线性代数(矩阵类)计算时会用到.kaldi工具的概貌文档,初步入门,强烈建议先读此文.
kaldi特征提取
MFCC
compute-mfcc-feats.cc
其中参数rspecifier用于读取.wav文件,wspecifier用于写入得到的MFCC特征。典型应用中,特征将被写入到一个大的”archive”文件,同时会写入一个”scp”文件用于随机存取。该程序并未提取delta特征(add-delats.cc). 其–channel参数用于选择立体声情况(–channel=0, –channel=1).Create MFCC feature files. Usage: compute-mfcc-feats [options...] <wav-rspecifier> <feats-wspecifier>
第一个参数”scp:…”用于读取exp/make_mfcc/train/wav1.scp指定的文件。第二个参数”ark:…”指示计算得到的特征写入归档文件/data/mfcc/raw_mfcc_train.1.ark。归档文件里的每一句是N(frames)× N(mfcc)的特征矩阵。 MFCC特征的计算是在对象MFCC中的compute方法完成的,计算过程如下: 1.遍历每一帧(通常25ms一帧,10ms滑动) 2.对每一帧 a.提取数据,添加可选扰动,预加重和去直流,加窗 b.计算该点的能量(使用对数能量,而非C0) c.做FFT并计算功率谱 d.计算每个梅尔频点的能量,共计23个重叠的三角频点,中心频率根据梅尔频域均匀分布。 e.计算对数能量,做离散余弦变换,保留指定的系数个数 f.倒谱系数加权,确保系数处于合理的范围。compute-mfcc-feats --config=conf/mfcc.conf \ scp:exp/make_mfcc/train/wav1.scp \ ark:/data/mfcc/raw_mfcc_train.1.ark;
三角梅尔频点的上下限由–low-freq和–high-freq决定,通常被分别设置成接近0和奈奎斯特频率。如对于16KHz语音–low-freq=20, –high-freq=7800。 可以使用copy-feats.cc将特征转换成其它格式。
倒谱均值和方差归一化
该归一化通常是为了获得基于说话人或者基于说话语句的零均值,单位方差归一化特征倒谱。但是并不推荐使用这个方法,而是使用基于模型的均值和方差归一化,如Linear VTLN(LVTLN)。可以使用基于音素的小语言模型进行快速归一化。特征提取代码compute-mfcc-feats.cc/compute-plp-feats.cc同样提供了–substract-mean选项获得零均值特征。如果要获得基于说话人或者基于句子的均值和方差归一化特征,可以使用 compute-cmvn-states.cc或者apply-cmvn.cc程序。 compute-cmvn-stats.cc将会计算均值和方差需要的所有统计量,并将这些统计信息以矩阵的形式写入到table中。
compute-cmvn-stats
--spk2utt=ark:data/train/train.1k/spk2utt \
scp:data/train.1k/feats.scp \
ark:exp/mono/cmvn.ark;
kaldi声学模型
- 支持标准的基于ML训练的模型
- 线性变换,如LDA,HLDA,MLLT/STC
- 基于fMLLR,MLLR的说话人自适应
- 支持混合系统
- 支持SGMMs
- 基于fMLLR的说话人识别
- 模型代码,可以容易的修改扩展
声学模型训练过程
1.获得语料集的音频集和对应的文字集
可以提供更精确的对齐,发音(句子)级别的起止时间,但这不是必须的。
2.将获得的文字集格式化
kaldi需要各种格式类型的,训练过程中将会用到每句话的起止时间,每句话的说话人ID,文字集中用到的所有单词和音素。
3.从音频文件提取声学特征
MFCC或者PLP被传统方法广泛使用。对于NN方法有所差异。
4.单音素训练
单音素训练不使用当前音素之前或者之后的上下文信息,三音素则使用当前音素,之前的音素和之后的音素。
5.基于GMM/HMM的框架
1.将音频根据声学模型对齐 声学模型的参数在声学训练时获得,然而,这个过程可以使用训练和对齐的循环进行优化。这也称之为维特比(Viterbi)训练(包括前向-后向以及期望最大化密集计算过程),通过将音频和文字对齐,可以使用额外的训练算法提升和精细化参数模型。所以,每一个训练步骤会跟随一个对齐步骤。
2.训练三音素模型 单音素模型仅仅表示了单个音素的参数,但是音素是随着上下文变化的,三音素模型使用上下文的前后音素展现了音素的变化。 并不是所有的单音素组合都存在于提供的文字集中,总共有$pohems^3$个可能的三音素,但是训练集所包含的是一个有限的子集,并且出现的三音素组合也要有一定的次数以方便训练,音素决策树会将这些三音素聚类成更小的集合。
3.根据声学模型重新对齐音频&重新训练三音素模型 重复上述1,2步骤,并加入额外更精细的三音素模型训练,通常包括delta+delta-delta训练, LDA-MLLT以及SAT。对齐算法包括说话人对齐和FMLLR。
4.训练算法 Delta和Delta-delta算法计算特征的一阶和二阶导数,或者是动态参数以补充MFCC特征。 LDA-MLLT(Linear Discriminant Analysis – Maximum Likelihood Linear Transform), LDA根据降维特征向量建立HMM状态。MLLT根据LDA降维后的特征空间获得每一个说话人的唯一变换。MLLT实际上是说话人的归一化。 SAT(Speaker Adaptive Training)。SAT同样对说话人和噪声的归一化。
5.对齐算法
实际的对齐操作是一样的,不同文集使用不同的声学模型。

图13.1 kalid中高斯声学模型
GMM
- 高效似然估计
- 概率计算经过两个矩阵向量的相乘获得,可以使用优化的BLAS函数实现。
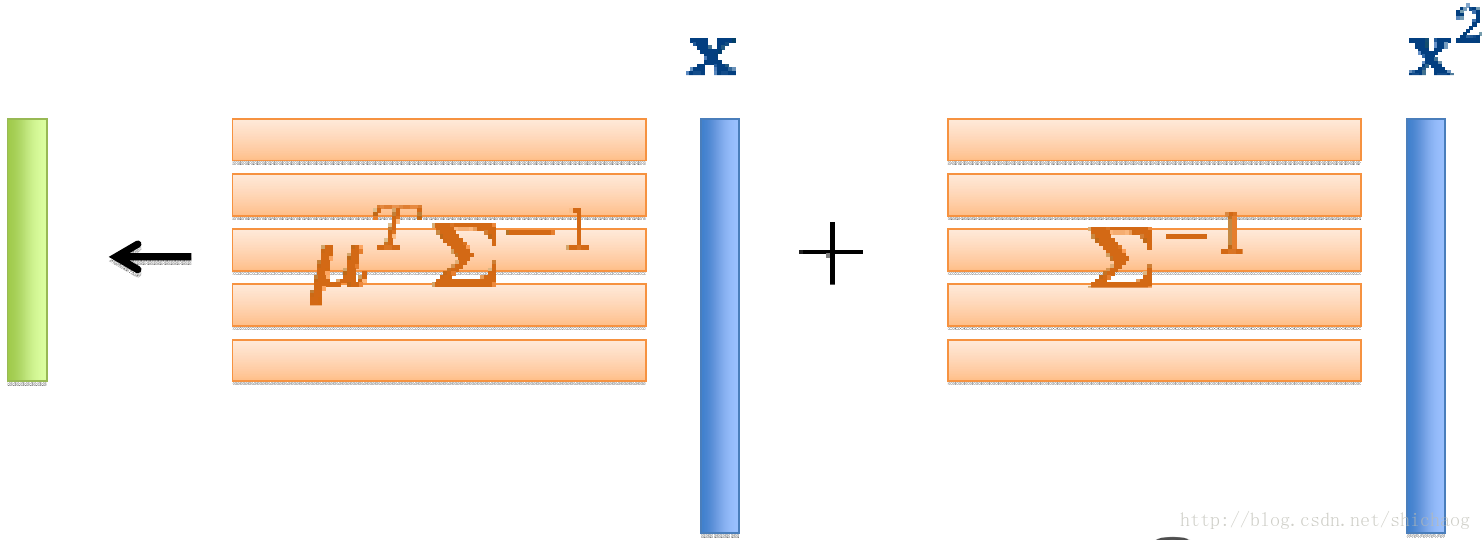
图13.2 概率矩阵的计算
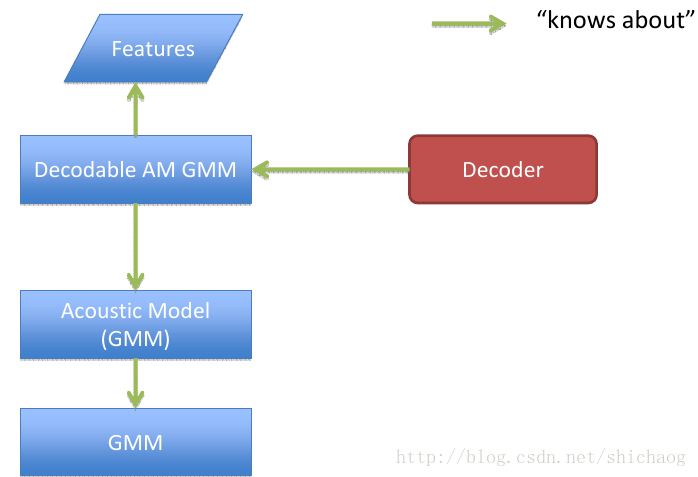
图13.3 kaldi中解码部分接口
class DecodableInterface{
public:
//Returns the log likelihood(negated in the decoder).
virtual BaseFloat LogLikelihood(int32 frame, int32 index)=0;
//Frames are one-based.
virtual bool IsLastFrame(int32 frame)=0;
//Indices are one-based(compatibility with OpenFst).
virtual int32 NumIndices()=0;
virtual ~DecodableInterface(){}
}
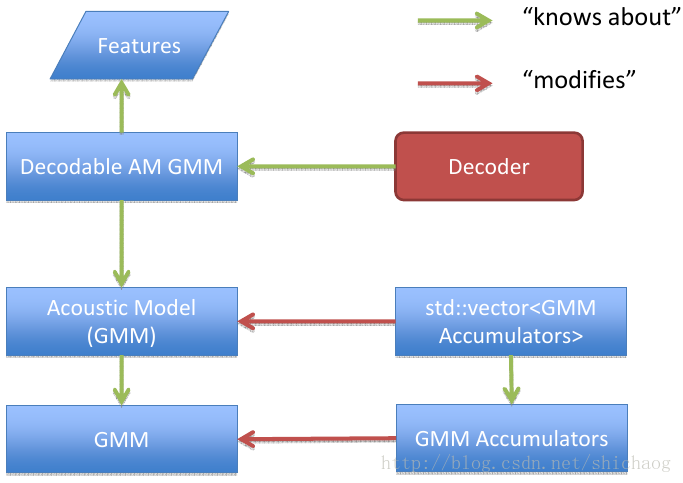
图13.4 声学模型训练
图13.5 fMLLR声学模型训练
图13.6 对角高斯声学模型
单音素训练
初始化单音素模型
-gmm-init-mono.cc 该程序有两个输入和两个输出。做为输入,需要描述声学模型的HMM音素结构的拓扑文件(如data/lang/topo)和高斯混合模型中每个分量的维度。 如:
gmm-init-mono data/lang/topo \
39 \
exp/mono/0.mdl \
exp/mono/tree;
在这个例子中tree是语境决策树。
-compile-train-graphs.cc 假设我们已经得到了决策树和模型。接下来的命令创建训练集对应的HCLG图归档文件。该程序为每一个训练语句编译FST。
compile-train-graphs exp/mono/tree \
exp/mono/0.mdl \
data/L.fst \
ark:data/train.tra \
ark:exp/mono/graphs.fsts;
train.tra是训练集的索引文件,该文件每一行的第一个字段是说话人ID。该程序的输出是graphs.fsts;其为train.tra中的每句话建立一个二进制格式的FST。该FST和HCLG对应,差异在于没有转移概率不在里面。这是因为该图将在训练中被多次用到且转移概率也将会发生变化,所以后面才会加上转移概率。但是归档的FST中包含了silence的概率(编码到L.fst)。解码图就是。 1.H包括了HMM定义;输出符号是上下文无关的音素,输入符号是一系列状态转变ID(是概率id和其它信息的编码)。 2.C代表的是上下文依赖关系。其输出代表音素的符号,输入是代表上下文相关的音素符号; 3.L是字典(Lexicon);输出是单词,输入是一系列音素。 4.G表示的是Grammar;是语音模型的有限状态机。
由于训练时候不要进行符号消歧义,所以图创建要比测试时简单,训练和测试使用HCLG形式上是一样的,不同在于,训练时G仅仅包括和训练文集相关的一个线性接收器。 同样希望HCLG具有随机性,传统方法使用“push-weights”方法。
训练单音素模型
-align-equal-compiled.cc 给定声学模型/图rspecifier/特征rspecifier。这个程序会返回用于对齐的wspecifier。这是EM算法中的E步骤. EM算法可以见 EM算法原理链接 EM算法源码链接
align-equal-compiled 0.mdl \
graphs.fsts \
scp:train.scp \
ark:equal.ali;
如果要查看对齐结果,可以使用show-alignments.cc程序查看。 -gmm-acc-stats-ali.cc 这个程序有三个输入:1.编译好的声学模型(0.mdl);2.训练用的音频文件特征(MFCC,train.scp)3.先前计算的隐藏状态的对齐信息。输出文件是GMM训练用的状态集(0.acc)。
gmm-acc-stats-ali 0.mdl \
scp:train.scp \
ark:equal.ali \
0.acc
-gmm-test.cc 这是EM算法的M步骤,给定1.声学模型; 2.GMM训练状态集,这个程序将会输出新的声学模型(经过ML估计更新)。
gmm-test --min-gaussian-occupancy=3 \
--mix-up=250 \
exp/mono/0.mdl \
exp/mono/0.acc \
exp/mono/1.mdl;
参数--mix-up指定了新的混合高斯模型成分的数量。
当训练数据量小时,--min-gaussian-occupancy需要指定以处理少见的音素。
音素和数据对齐
-gmm-align-compiled.cc 给定1.声学模型;2.图的rspecifier;3.特征的rspecifier。该程序返回对齐的wspecifier。这是EM算法中的E步骤。对齐是指HMM状态和提取的语音特征向量关系。每一个HMM状态有一个高斯分布输出,对齐后的特征向量会被用于高斯参数更新($\mu$和$\sum$).
gmm-align-compiled 1.mdl \
ark:graphs.fsts \
scp:train.scp \
ark:1.ali;
三音素训练
上下文相关音素决策数构建
CART(Clustering and Regression Tree).
-acc-tree-stats.cc
该程序有三个输入参数1.声学模型,2.声学特征的rspecifier,3.前一次对齐的rspecifier。返回值是树累积量。
该程序不仅能处理单音素对齐,也能处理基于上下文关系的对齐(如三音素),构建树需要的统计量被以BuildTreeStatsType类型写入磁盘,函数AccumulateTreeStats()接收P和N。命令行程序会将P和N缺省设置成3和1,但是可以使用--context-with和--central-position选项进行更改。acc-tree-stats.cc接收一系列上下文无关音素(如,silence),这可以减少统计量的数目。
acc-tree-stats final.mdl \
scp:train.scp \
ark:JOB.ali \
JOB.treeacc;
-sum-tree-statics.cc 该程序为音素树构建求和统计量,该程序输入多个*.treeacc文件,输出单个累积后统计量(如treeacc)。
sum-tree-stats treeacc \
phonesets.int \
questions.int;
-compile-questions.cc 该程序的输入是1.HMM拓扑(如,topo),2.音素列表(如,questions.int),返回EventMap(如phonesets.qst)中“key”对应问题的C++对象表示的音素列表。
compile-questions data/lang/topo \
exp/triphones/questions.int \
exp/triphones/questions.qst;
-build-tree.cc
当统计量累积后可以使用build-tree.cc构建树。其有三个输入参数:1.累积的树统计量(treeacc),2.问题配置(questions.qst),3.根文件(roots.int)。
树统计量使用程序acc-tree-stats.cc求得,问题配置使用程序compile-questions.cc求得,cluster-phones.cc求得音素问题拓扑列表。
build-tree建立了一系列决策树,最大叶子节点数(如2000)是概率数量,在分割之后,对每一颗树会做后聚类。共享的叶子的作用域在单棵树内。
build-tree treeacc \
roots.int \
questions.qst \
topo \
tree;
可以使用程序draw-tree.cc查看决策树。
draw-tree data/lang/phones.txt \
exp/mono/tree | \
dot -Tps -Gsize=8,10.5 | \
ps2pdf - ~/tree.pdf
-gmm-init-model.cc 根据1.决策树(tree),2.累积树状态(treeacc),3.HMM拓扑(topo)来初始化GMM声学模型(1.mdl)。
gmm-init-model tree \
treeacc \
topo \
1.mdl;
-gmm-mixup.cc 根据1.高斯声学模型(1.mdl),2.每个状态转变ID出现次数,做高斯合并操作,返回的高斯声学模型(2.mdl)的分量数会增加。
gmm-mixup --mix-up=$numgauss \
1.mdl \
1.occs \
2.mdl
-convert-ali.cc 根据1.旧的GMM模型(monophones_aligned/final.mdl),2.新的GMM模型(triphones_del/2.mdl),3.新的决策树(triphones_del/tree),4.就的对齐的rspecifier(monophones_aligned/ali..gz),该程序将返回新的对齐(triphones_del/ali..gz)。
convert-ali monophones_aligned/final.mdl \
triphones_del/2.mdl \
triphones_del/tree \
monophones_aligned/ali.*.gz \
triphones_del/ali.*.gz
-compile-train-graphs.cc 给定输入1.决策树(tree),2.声学模型(2.mdl),3.字典的有限状态转换器(L.fst),4.训练文本集的rspecifier(text)将输出训练图的wspecifier(fsts.*.gz)。
compile-train-graphs tree \
1.mdl \
L.fst \
text \
fsts.*.gz;
WFST关键点
1.determinization 2.minimization 3.composition 4.equivalent 5.epsilon-free 6.functional 7.on-demand algorithm 8.weight-pushing 9.epsilon removal
HMM关键点
1.Markov Chain 2.Hidden Markov Model 3.Forward-backward algorithm 4.Viterbi algorithm 5.E-M for mixture of Gaussians
L.fst 发音字典FST
L将单音素序列映射到单词。 文件L.fst是根据音素符号序列获得单词序列的有限状态转换器。
聚类机制
类GaussClusterable(高斯统计量)继承了纯虚类Clusterable。未来会加入从Clusterable类继承来的可以聚类对象的处理。Clusterable 存在的目的是使用通用聚类算法。 Clusterable的核心思想是将统计量相加,然后评测目标函数,两个可以聚类对象的距离是指两个对象各自目标函数和他们相加之后目标函数带来的影响。 Clusterable类相加的实例有混合高斯统计量的高斯模型,离散观测量的计数值。 获得Clusterable*对象的实例如下:
Vector<BaseFloat> x_stats(10), x2_stats(10);
BaseFloat count = 100.0, var_floor = 0.01;
// initialize x_stats and x2_stats e.g. as
// x_stats = 100 * mu_i, x2_stats = 100 * (mu_i*mu_i + sigma^2_i)
Clusterable *cl = new GaussClusterable(x_stats, x2_stats, var_floor, count);
聚类算法
聚类函数如下:
- ClusterBottomUp
- ClusterBottomUpCompartmentalized
- RefineClusters
- ClusterKMeans
- TreeCluster
- ClusterTopDown 常用到的数据类型是:
std::vector<Clusterable*> to_be_clustered;
K-means及其类似算法接口
聚类代码调用实例如下:
std::vector<Clusterable*> to_be_clustered;
// initialize "to_be_clustered" somehow ...
std::vector<Clusterable*> clusters;
int32 num_clust = 10; // requesting 10 clusters
ClusterKMeansOptions opts; // all default.
std::vector<int32> assignments;
ClusterKMeans(to_be_clustered, num_clust, &clusters, &assignments, opts);
ClusterBottomUp() 和ClusterTopDown()和ClusterKMeans()的调用方法类似,如果聚类的数量较大,ClusterTopDown()比ClusterKMeans()更高效。
HMM拓扑
使用c++的HmmTopology来描述音素的HMM拓扑。其描述的一个实例(3-state Bakis模型)如下:
<Topology>
<TopologyEntry>
<ForPhones> 1 2 3 4 5 6 7 8 </ForPhones>
<State> 0 <PdfClass> 0
<Transition> 0 0.5
<Transition> 1 0.5
</State>
<State> 1 <PdfClass> 1
<Transition> 1 0.5
<Transition> 2 0.5
</State>
<State> 2 <PdfClass> 2
<Transition> 2 0.5
<Transition> 3 0.5
</State>
<State> 3
</State>
</TopologyEntry>
</Topology>
在这个实例中只有一个TopologyEntry,其包括了音素1~8(所以这个例子总共8个音素,这些音素共享相同的拓扑)。有三个发射状态,每个状态包括一个自循环和发射到其它状态的概率。还有最后一个非发射状态(状态3,没有HmmTopology 对象中的概率用于初始化训练。训练的概率是上下文相关的HMM并且存储在TransitionModel对象。TransitionModel以c++类成员的方式存储HmmTopology对象。HmmTopology的转换概率通常除了初始化TransitionModel对象其它地方并不会被用到。
Pdf-class
Pdf-class是和对象HmmTopology有关的一个对象。HmmTopology为每一个音素指定了一个HMM模型,每一个有编号的状态有两个变量forward_pdf_class和self_loop_pdf_class。self_loop_pdf_class是转换到状态自身的概率,缺省值是和forward_pdf_class一样的。但是两者的概率也可以不一样。
音素的HMM状态通常从0开始,连续的(1,2,。。。),这是为了图构建的方便。
状态转换模型(TransitionModel对象)
TransitionModel对象存储了音素的HMM拓扑对应的转变概率和信息。构建图的代码根据TransitionModel和ContextDependencyInterface对象来获得拓扑结构和状态转换概率。
状态转化概率建模
状态转换的概率是和上下文相关的HMM状态相关的,其依赖如下5项内容(5元组):
- 音素
- 源HMM状态(
HmmTopology对象解析,通常是0,1,2...) - 前向概率(
forward-pdf-id,) - 自循环概率(
self-loop-pdf-id) HmmTopology对象的状态索引 后四项可以看成是目标HMM状态编码成HmmTopology对象。transition-idsTrainsitionModel对象在初始化时建立了音素和整数之间的映射关系,此外还有转换标识符 (transition identifiers)transition-ids,转换索引(transition indexes),转换状态(transition states)这些量。引入这些量为了完全使用基于FST的训练方法。TransitionModel使用的整型标识符- 音素(从1开始):可以从OpenFst符号表转换成音频的名字,并不要求音素是连续标号的。
- hmm状态(从0开始):用于索引
HmmTopology::TopologyEntry对象。 - 概率或者pdf-ids(从0开始):源于决策树聚类后结果,通常一个ASR系统有数以千计的pdf-id.
transition-state(从1开始):TransitionModel定义。每一个可能的三元组(音素,hmm状态,概率)映射到一个独一无二的转换状态。transition-index(从0开始):是对HmmTopology::HmmState的索引。transition-id(从1开始):是状态转换模型的转换概率。二元组(transition-state,transition-index)和transition-id可以互相映射。
- 源HMM状态(
转换模型(transition model)训练
用于训练和测试的FST将transition-id做为输入label。在训练过程中使用维特比解码获得输入transition-id序列(每一个都是一个特征向量),函数Transition::Update()对每个transition-state做最大似然估计。
对齐
和的语句长度一样的包含一系列transition-ids的vectortransition-ids序列从解码器得到。对齐用于维特比训练和测试时自适应。由于transition-ids编码了音素信息,可以通过工具SplitToPhones()和ali-to-phones.cc根据对齐取出音素序列。
通常kaldi中需要处理由句子索引的对齐集合,这通常使用表的方式来实现。
函数ConvertAlignment()(命令行是convert-ali)将对齐从一个状态转变模型转换到另一个模型。
状态层次后验概率
状态级后验概率是“对齐”概念的扩展,区别在于“对齐”概念上每帧对应一个状态转变ID,而状态级后验概率每帧的状态转变ID的数量没有限制,且每个状态ID都有一个权重对应。通常按如下结构存储:
typedef std::vector<std::vector<std::pair<int32, BaseFloat> > > Posterior;
如果使用Posterior创建了一个名为post的对象,则post.size()将等于句子帧数,post[i]存储的是(transition-id, posterior)信息。
当前程序中,只有两个方法创建posteriors。
- 使用
ali-to-post程序将对齐转换成后延概率。 - 使用
weight-silence-post修改后验概率。 当加入lattice是,也有工具从Lattice生成后验概率。
高斯层次后验概率
表示高斯层次的后验概率类型如下:
typedef std::vector<std::vector<std::pair<int32, Vector<BaseFloat> > > > GauPost;
其状态是使用向量浮点数来表示的。向量的size和高斯量的数目是一样的。post-to-gpost将Posterior结构转换成GauPost结构。使用模型和特征计算高斯层次的后验概率。
HMMs转成FSTs
GetHTransducer()
fst::VectorFst<fst::StdArc>*
GetHTransducer (const std::vector<std::vector<int32> > &ilabel_info,
const ContextDependencyInterface &ctx_dep,
const TransitionModel &trans_model,
const HTransducerConfig &config,
std::vector<int32> *disambig_syms_left);
该函数返回输入是transition-ids,输出是上下文相关音素的FST。FST具有初始和终止状态,转换出FST的状态变换将输出音素符号。通常转出FST状态会转入一个表示3状态HMM的结构体中,然后跳到起始状态。
HTransducerConfig配置类
HTransducerConfig控制着GetHTransducer的行为。
- 变量
trans_prob_scale是状态转变缩放因子。当转变概率添加到图里时,会乘以缩放因子。命令行工具是transition-scale。GetHmmAsFst()
函数GetHmmAsFst()输入是一段音素,返回的是状态机最终状态时得到的transition-ids序列。
AddSelfLoops()
是向图中添加自循环。添加自循环的意义是可以进行状态重新调整,而不加的意义在于决策过程可以更高效。
FST添加状态转变概率
函数AddTransitionProbs()向FST添加概率。这样可以在无概率时就可以创建图了。
yes/no实例
这个例子可以和第十五章基于tensorflow的yes/no实例进行对比. tensorflow yes/no实例
数据描述
如果kaldi/egs/yesno/s5目录下没有waves_yesno.tar.gz文件,则要下载该文件. http://www.openslr.org/resources/1/waves_yesno.tar.gz 解压后,waves_yesno文件夹下的文件如下.
0_0_0_0_1_1_1_1.wav 0_0_1_1_0_1_1_0.wav
...
1_1_1_0_1_0_1_1.wav
总共60个wav文件,采样率都是8k,wav文件里每一个单词要么"ken"要么"lo"("yes"和"no")的发音,所以每个文件有8个发音,文件命名中的1代表yes发音,0代表no的发音.
数据预处理
wav文件预处理
local/prepare_data.sh waves_yesno
local/prepare_dict.sh
utils/prepare_lang.sh --position-dependent-phones false data/local/dict "<SIL>" data/local/lang data/lang
local/prepare_lm.sh
- 生成wavelist文件
上述shell命令就是把waves_yeno目录下的文件名全部保存到waves_all.list中.ls -1 $waves_dir > data/local/waves_all.list
local/create_yesno_waves_test_train.pl waves_all.list waves.test waves.train
- 生成waves.test和waves.train
将waves_all.list中的60个wav文件,分成两拨,各30个,分别放在waves.test和waves.train中.
如waves.train文件内容如下:
0_0_0_0_1_1_1_1.wav 生成test_yesno_wav.scp和train_yesno_wav.scp 根据waves.test 和waves.train又会生成test_yesno_wav.scp和train_yesno_wav.scp两个文件. 这两个文件内容排列格式如下
<file_id> <wave filename with path OR command to get wave file> 如: 0_0_0_0_1_1_1_1 waves_yesno/0_0_0_0_1_1_1_1.wav其中由于训练的scp文件如下:
生成train_yesno.txt和test_yesno.txt 这两个文件存放的是发音id和对应的文本.
<utt_id><transcript> 如: 0_0_1_1_1_1_0_0 NO NO YES YES YES YES NO NO- 生成utt2spk和spk2utt
这个两个文件分别是发音和人对应关系,以及人和其发音id的对应关系.由于只有一个人的发音,所以这里都用global来表示发音.
```
utt2spk
0_0_1_0_1_0_1_1 global
utt2spk
此外还可能会有如下文件(这个例子没有用到):
- segments
包括每个录音的发音分段/对齐信息
只有在一个文件包括多个发音时需要
- reco2file_and_channel
双声道录音情况使用到
- spk2gender
将说话人和其性别建立映射关系,用于声道长度归一化.
以上生成的文件经过辅助操作均在:
data/train_yesno/ data/test_yesno/
目录结构如下:
data ├───train_yesno │ ├───text │ ├───utt2spk │ ├───spk2utt │ └───wav.scp └───test_yesno ├───text ├───utt2spk ├───spk2utt └───wav.scp
####字典准备
构建语言学知识-词汇和发音词典.需要用到steps和utils目录下的工具。这可以通过修改该目录下的path.sh文件进行更新。
首先创建词典目录
mkdir -p data/local/dict
这个简单的例子只有两个单词:YES和NO,为简单起见,这里假设这两个单词都只有一个发音:Y和N。这个例子直接拷贝了相关的文件,非语言学的发音,被定义为SIL。
data/local/dict/lexicon.txt
- lexicon.txt,完整的词位-发音对
- lexicon_words.txt,单词-发音对
- silence_phones.txt, 非语言学发音
- nonsilence_phones.txt,语言学发音
- optional_silence.txt ,备选非语言发音
最后还要把字典转换成kaldi可以接受的数据结构-FST(finit state transducer)。这一转换使用如下命令:
utils/prepare_lang.sh --position-dependent-phones false data/local/dict "
由于语料有限,所以将位置相关的发音disable。这个命令的各行意义如下:
utils/prepare_lang.sh --position-dependent-phones false
OOV存放的是词汇表以外的词,这里就是静音词(非语言学发声意义的词)
发音字典是二进制的OpenFst 格式,可以使用如下命令查看:
gsc@X250:~/kaldi/egs/yesno/s5$ ~/kaldi/tools/openfst-1.6.2/bin/fstprint --isymbols=data/lang/phones.txt --osymbols=data/lang/words.txt data/lang/L.fst
0 1
####语言学模型
这里使用的是一元文法语言模型,同样要转换成FST以便kaldi接受。该语言模型原始文件是data/local/lm_tg.arpa,生成好的FST格式的。是字符串和整型值之间的映射关系,kaldi里使用整型值。
gsc@X250:~/kaldi/egs/yesno/s5$ head -5 data/lang/phones.txt
可以使用如下命令查看生成音素的树形结构:
###phone 树
~/kaldi/src/bin/draw-tree data/lang/phones.txt exp/mono0a/tree | dot -Tps -Gsize=8,10.5 | ps2pdf - ./tree.pdf

>图13.1 音素树
LM(language model)在data/lang_test_tg/。
local/prepare_lm.sh
####查看拓扑结构

在<ForPhone> </ForPhones>之间的数字,1表示silcense,2,3分别表示Y和N,这从拓扑图里也可以看出来。
指定了三个状态从左到右的HMM以及默认的转变概率。为silence赋予5个状态。

>图13.2 模型
0.mdl的内容如上:
####转移模型
####音素 hmm状态
####高斯模型
如下的20+1个log概率对应于11个phone(0-10)。
接下来是高斯模型的维度39维(没有能量),对角GMM参数总共11个。
在接下来就是对角高斯参数的均值方差权重等参数:
####编译训练图

为每一个训练的发音编译FST,为训练的发句编码HMM结构。
####kaldi 中表的概念
>表是字符索引-对象的集合,有两种对象存储于磁盘
>“scp”(script)机制:.scp文件从key(字串)映射到文件名或者pipe
>“ark”(archive)机制:数据存储在一个文件中。
Kaldi 中表
一个表存在两种形式:"archive"和"script file",他们的区别是archive实际上存储了数据,而script文件内容指向实际数据存储的索引。
从表中读取索引数据的程序被称为"rspecifier",向表中写入字串的程序被称为"wspecifier"。
| rspecifier | meaning |
| ------------- |:-------------:|
| ark:- | 从标准输入读取到的数据做为archive |
| scp:foo.scp | foo.scp文件指向了去哪里找数据 |
冒号后的内容是wxfilename 或者rxfilename,它们是pipe或者标准输入输出都可以。
表只包括一种类型的对象(如,浮点矩阵)
respecifier和wspecifier可以包括一些选项:
- 在respecifier中,ark,s,cs:- ,表示当从标准输入读操作时,我们期望key是排序过的(s),并且可以确定它们将会按排序过的顺序读取,(cs)意思是我们知道程序将按照排序过的方式对其进行访问(如何条件不成立,程序会crash),这是得Kaldi不要太多内存下可以模拟随机访问。
* 对于数据源不是很大,并且结果和排序无关的情形时,rspecifier可以忽略s,cs。
* scp,p:foo.scp ,p表示如果scp索引的文件存在不存在的情况,程序不crash(prevent of crash)。
* 对于写,选项t表示文本模式。
script文件格式是,`<key> <rspecifier|wspecifier>`如`utt1 /foo/bar/utt1.mat`
从命令行传递的参数指明如何读写表(scp,ark)。对于指示如何读表的字串称为“rspecifier”,而对写是"wspecifier"。
写表的实例如下:
| wspecifier | 意义 |
| ------------- |:-------------:|
| ark:foo.ark | 写入归档文件foo.ark |
| scp:foo.scp | 使用映射关系写入foo.scp |
| ark:- | 将归档信息写入stdout |
| ark,t:\|gzip -c > foo.gz | 将文本格式的归档写入foo.gz |
| ark,t:- | 将文本格式的归档写入 stdout |
| srk,scp:foo.ark, foo.scp | 写归档和scp文件 |
读表:
| rspecifier | 意义 |
| ------------- |:-------------:|
| ark:foo.ark | 读取归档文件foo.ark |
| scp:foo.scp | 使用映射关系读取foo.scp |
| scp,p:foo.scp | 使用映射关系读取foo.scp,p:如果文件不存在,不报错 |
| ark:- | 从标准输入读取归档 |
| ark:gunzip -c foo.gz\| | 从foo.gz读取归档信息 |
| ark,s,cs:- | 从标准输入读取归档后排序 |
###特征提取和训练
####特征提取,这里是做mfcc。
steps/make_mfcc.sh --nj
for x in train_yesno test_yesno; do steps/make_mfcc.sh --nj 1 data/$x exp/make_mfcc/$x mfcc steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x mfcc utils/fix_data_dir.sh data/$x done
该脚本主要执行的命令是:
gsc@X250:~/kaldi/egs/yesno/s5$ head -3 exp/make_mfcc/train_yesno/make_mfcc_train_yesno.1.log
compute-mfcc-feats --verbose=2 --config=conf/mfcc.conf scp,p:exp/make_mfcc/train_yesno/wav_train_yesno.1.scp ark:- | copy-feats --compress=true ark:- ark,scp:/home/gsc/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.ark,/home/gsc/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.scp
copy-feats --compress=true ark:- ark,scp:/home/gsc/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.ark,/home/gsc/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.scp compute-mfcc-feats --verbose=2 --config=conf/mfcc.conf scp,p:exp/make_mfcc/train_yesno/wav_train_yesno.1.scp ark:-
archive文件存放的是每个发音对应的特征矩阵(帧数X13大小)。
第一个参数{% math %}scp:...{% endmath %}指示在[dir]/wav1.scp里罗列的文件。

通常在做NN训练时,提取的是40维度,包括能量和上面的一阶差分和二阶差分。
~/kaldi/src/featbin/copy-feats ark:raw_mfcc_train_yesno.1.ark ark:- |~/kaldi/src/featbin/add-deltas ark:- ark,t:- | head
然后归一化导谱特征系数
steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x mfcc
生成的文件最终在mfcc目录下:
cmvn_test_yesno.ark
cmvn_train_yesno.ark
raw_mfcc_test_yesno.1.ark
raw_mfcc_train_yesno.1.ark
cmvn_test_yesno.scp
cmvn_train_yesno.scp
raw_mfcc_test_yesno.1.scp
raw_mfcc_train_yesno.1.scp
详细各个命令意义,参考kaldi官网文档http://kaldi-asr.org/doc/tools.html
###单音节训练
steps/train_mono.sh --nj
steps/train_mono.sh --nj 1 --cmd "$train_cmd" \ --totgauss 400 \ data/train_yesno data/lang exp/mono0a
这将生成语言模型的FST,
使用如下命令可以查看输出:
fstcopy 'ark:gunzip -c exp/mono0a/fsts.1.gz|' ark,t:- | head -n 20

其每一列是(Q-from, Q-to, S-in, S-out, Cost)
###解码和测试
####图解码
首先测试文件也是按此生成。
然后构建全连接的FST。
utils/mkgraph.sh data/lang_test_tg exp/mono0a exp/mono0a/graph_tgpr
解码
Decoding
steps/decode.sh --nj 1 --cmd "$decode_cmd" \ exp/mono0a/graph_tgpr data/test_yesno exp/mono0a/decode_test_yesno
这将会生成`lat.1.gz`,该文件包括发音格。`exp/mono/decode_test_yesno/wer_X`并且也计算了词错误率。`exp/mono/decode_test_yesno/scoring/X.tra`是文本。X是语言模型权重LMWT。当然也可以在调用`score.sh`添加参数`--min_lmwt 和 --max_lmwt`进行修改。
###结果查看
for x in exp//decode; do [ -d $x ] && grep WER $x/wer_* | utils/best_wer.sh; done
``
如果对单词级别的对齐信息感兴趣,可以参考steps/get_ctm.sh`